Worauf basiert die Hauptkomponentenmethode? Anwendung der Hauptkomponentenmethode zur Verarbeitung multivariater statistischer Daten. Anwendung der Hauptkomponentenanalyse
Hauptkomponentenmethode(PCA - Principal Component Analysis) ist eine der Hauptmethoden, um die Dimension von Daten mit dem geringsten Informationsverlust zu reduzieren. 1901 von Karl Pearson erfunden, ist es in vielen Bereichen weit verbreitet. Zum Beispiel für Datenkomprimierung, "Computer Vision", sichtbare Mustererkennung usw. Die Berechnung von Hauptkomponenten reduziert sich auf die Berechnung von Eigenvektoren und Eigenwerten der Kovarianzmatrix der Originaldaten. Die Hauptkomponentenmethode wird oft als bezeichnet Karhunen-Löwe-Transformation(Karhunen-Loeve-Transformation) oder Hotelling verwandeln(Hoteltransformation). Auch die Mathematiker Kosambi (1943), Pugachev (1953) und Obukhova (1954) arbeiteten an diesem Thema.
Das Problem der Hauptkomponentenanalyse zielt darauf ab, Daten durch lineare Mannigfaltigkeiten niedrigerer Dimension zu approximieren (annähern); finden Sie Unterräume niedrigerer Dimension in der orthogonalen Projektion, auf denen die Datenstreuung (dh die Standardabweichung vom Mittelwert) maximal ist; Finden Sie Unterräume niedrigerer Dimension in der orthogonalen Projektion, auf die der quadratische Mittelabstand zwischen Punkten maximal ist. In diesem Fall arbeitet man mit endlichen Datensätzen. Sie sind gleichwertig und verwenden keine Hypothesen zur statistischen Datengenerierung.
Darüber hinaus kann die Aufgabe der Hauptkomponentenanalyse das Ziel sein, für eine gegebene mehrdimensionale Zufallsvariable eine solche orthogonale Transformation von Koordinaten zu konstruieren, dass im Ergebnis die Korrelationen zwischen einzelnen Koordinaten verschwinden. Diese Version arbeitet mit Zufallsvariablen.
Abb. 3
Die obige Abbildung zeigt Punkte P i auf der Ebene, p i ist der Abstand von P i zur Linie AB. Suche nach einer Geraden AB, die die Summe minimiert
Die Methode der Hauptkomponenten begann mit dem Problem der besten Annäherung (Approximation) einer endlichen Menge von Punkten durch Geraden und Ebenen. Zum Beispiel bei einer endlichen Menge von Vektoren. Für jedes k = 0,1,...,n ? 1 unter allen k-dimensionalen linearen Mannigfaltigkeiten in finden, so dass die Summe der quadrierten Abweichungen von x i von L k minimal ist:
wo? Euklidischer Abstand von einem Punkt zu einer linearen Mannigfaltigkeit.
Jede k-dimensionale lineare Mannigfaltigkeit in kann als Satz von Linearkombinationen definiert werden, wobei die Parameter in i durch die reelle Gerade laufen, oder? orthonormaler Satz von Vektoren
wo ist die euklidische norm, ? Euklidisches Punktprodukt oder in Koordinatenform:
Lösung des Näherungsproblems für k = 0,1,...,n ? 1 ist durch einen Satz verschachtelter linearer Mannigfaltigkeiten gegeben
Diese linearen Mannigfaltigkeiten werden durch einen orthonormalen Satz von Vektoren (Hauptkomponentenvektoren) und einen Vektor a 0 definiert. Als Lösung des Minimierungsproblems für L 0 wird der Vektor a 0 gesucht:


Das Ergebnis ist ein Stichprobenmittelwert:
Der französische Mathematiker Maurice Frechet Frechet Maurice René (02.09.1878 - 04.06.1973) ist ein herausragender französischer Mathematiker. Er arbeitete auf dem Gebiet der Topologie und Funktionalanalysis, Wahrscheinlichkeitstheorie. Autor moderne Konzepteüber metrischen Raum, Kompaktheit und Vollständigkeit. Auth. bemerkten 1948, dass die Variationsdefinition des Mittelwerts als ein Punkt, der die Summe der quadrierten Abstände zu Datenpunkten minimiert, sehr praktisch ist, um Statistiken in einem beliebigen metrischen Raum zu erstellen, und erstellten eine Verallgemeinerung der klassischen Statistik für allgemeine Räume, die als verallgemeinerte Methode bezeichnet wird der kleinsten Quadrate.
Hauptkomponentenvektoren können als Lösungen für ähnliche Optimierungsprobleme gefunden werden:
1) Zentralisieren Sie die Daten (subtrahieren Sie den Durchschnitt):
2) finde die erste Hauptkomponente als Lösung des Problems;

3) Subtrahiere von den Daten die Projektion auf die erste Hauptkomponente:
4) Finden Sie die zweite Hauptkomponente als Lösung des Problems

Wenn die Lösung nicht eindeutig ist, wählen Sie eine davon aus.
2k-1) Subtrahieren Sie die Projektion auf die (k ? 1)-te Hauptkomponente (denken Sie daran, dass die Projektionen auf die vorherigen (k ? 2) Hauptkomponenten bereits subtrahiert wurden):
2k) finden wir k-te Haupt Komponente als Lösung des Problems:

Wenn die Lösung nicht eindeutig ist, wählen Sie eine davon aus.

Reis. vier
Die erste Hauptkomponente maximiert die Stichprobenvarianz der Projektion der Daten.
Nehmen wir zum Beispiel an, wir erhalten einen zentrierten Satz von Datenvektoren, bei denen das arithmetische Mittel von x i null ist. Eine Aufgabe? Finden Sie eine solche orthogonale Transformation zu einem neuen Koordinatensystem, für das die folgenden Bedingungen gelten würden:
1. Die Stichprobenvarianz der Daten entlang der ersten Koordinate (Hauptkomponente) ist maximal;
2. Die Stichprobenvarianz von Daten entlang der zweiten Koordinate (der zweiten Hauptkomponente) ist unter der Bedingung der Orthogonalität zu der ersten Koordinate maximal;
3. Die Probenstreuung der Daten entlang der Werte der k-ten Koordinate ist maximal unter der Bedingung der Orthogonalität zum ersten k ? 1 Koordinaten;
Die Stichprobenvarianz der Daten entlang der durch den normalisierten Vektor a k gegebenen Richtung ist
(Da die Daten zentriert sind, ist die Stichprobenvarianz hier gleich der mittleren quadratischen Abweichung von Null).
Das Lösen des Best-Fit-Problems ergibt aus einem sehr einfachen Grund denselben Satz von Hauptkomponenten wie das Finden orthogonaler Projektionen mit der größten Streuung:
und der erste Term hängt nicht von a k ab.
Die Datenumwandlungsmatrix in Hauptkomponenten wird aus den Vektoren "A" der Hauptkomponenten erstellt:
Hier sind a i orthonormale Spaltenvektoren von Hauptkomponenten, die in absteigender Reihenfolge der Eigenwerte angeordnet sind, hochgestelltes T bedeutet Transposition. Die Matrix A ist orthogonal: AA T = 1.
Nach der Transformation konzentriert sich der größte Teil der Datenvariation auf die ersten Koordinaten, was es ermöglicht, die verbleibenden zu verwerfen und einen Raum mit reduzierter Dimension zu betrachten.
Die älteste Hauptkomponentenauswahlmethode ist Kaisers Herrschaft, Kaiser Johann Henrich Gustav (Kaiser Johann Henrich Gustav, 16.03.1853, Brezno, Preußen - 14.10.1940, Deutschland) - ein herausragender deutscher Mathematiker, Physiker, Forscher auf dem Gebiet der Spektralanalyse. Auth. wonach diese Hauptbestandteile für welche von Bedeutung sind
das heißt, l i übersteigt den Mittelwert von l (die mittlere Stichprobenvarianz der Koordinaten des Datenvektors). Die Kaiser-Regel funktioniert gut in einfachen Fällen, in denen mehrere Hauptkomponenten mit l i vorhanden sind, die viel größer als der Mittelwert sind, und der Rest der Eigenwerte kleiner als er ist. In komplexeren Fällen kann es zu viele signifikante Hauptkomponenten geben. Normalisiert man die Daten entlang der Achsen auf die Einheitsstichprobenvarianz, dann nimmt die Kaiser-Regel eine besonders einfache Form an: Nur die Hauptkomponenten sind signifikant, für die l i > 1 ist.
Einer der beliebtesten heuristischen Ansätze zum Schätzen der Anzahl der benötigten Hauptkomponenten ist Gebrochene Zuckerrohrregel, wenn die Menge der Eigenwerte (, i = 1, ... n), die auf die Einheitssumme normalisiert sind, mit der Längenverteilung der Fragmente eines Stocks der Einheitslänge verglichen wird, der bei n gebrochen ist? 1. zufällig ausgewählter Punkt (die Bruchstellen werden unabhängig voneinander ausgewählt und sind gleichmäßig über die Länge des Stocks verteilt). Wenn L i (i = 1,...n) die Längen der erhaltenen Rohrstücke sind, in absteigender Reihenfolge der Länge nummeriert: , dann ist der Erwartungswert von L i:

Betrachten wir ein Beispiel, das darin besteht, die Anzahl der Hauptkomponenten gemäß der Broken Cane Rule in Dimension 5 zu schätzen.

Reis. 5.
Nach der Regel gebrochen Stöcke k-th ein Eigenvektor (in absteigender Reihenfolge der Eigenwerte l i) wird in der Liste der Hauptkomponenten gespeichert, wenn
Die obige Abbildung zeigt ein Beispiel für den 5-dimensionalen Fall:
l1 = (1+1/2+1/3+1/4+1/5)/5; l2 = (1/2+1/3+1/4+1/5)/5; l 3 \u003d (1/3 + 1/4 + 1/5) / 5;
l 4 \u003d (1/4 + 1/5) / 5; l 5 \u003d (1/5) / 5.
Zum Beispiel ausgewählt
0.5; =0.3; =0.1; =0.06; =0.04.
Gemäß der Regel eines gebrochenen Stocks sollten in diesem Beispiel 2 Hauptkomponenten übrig bleiben:
Es sollte nur beachtet werden, dass die Broken Cane Rule dazu neigt, die Anzahl der signifikanten Hauptkomponenten zu unterschätzen.
Nach dem Projizieren auf die ersten k Hauptkomponenten c ist es zweckmäßig, entlang der Achsen auf die Varianz der Einheit (Stichprobe) zu normalisieren. Die Streuung entlang der i-ten Hauptkomponente ist gleich), daher muss zur Normierung die entsprechende Koordinate durch dividiert werden. Diese Transformation ist nicht orthogonal und bewahrt das Skalarprodukt nicht. Nach der Normalisierung wird die Kovarianzmatrix der Datenprojektion zu Eins, die Projektionen in zwei beliebige orthogonale Richtungen werden zu unabhängigen Werten und jede orthonormale Basis wird zur Basis der Hauptkomponenten (denken Sie daran, dass die Normalisierung das Orthogonalitätsverhältnis der Vektoren ändert). Die Abbildung vom anfänglichen Datenraum auf die ersten k Hauptkomponenten zusammen mit der Normierung ist durch die Matrix gegeben

Diese Transformation wird am häufigsten als Karhunen-Loeve-Transformation bezeichnet, d. h. die Methode der Hauptkomponenten selbst. Hier sind a i Spaltenvektoren und hochgestelltes T bedeutet Transponieren.
In der Statistik werden bei der Anwendung der Hauptkomponentenmethode mehrere Fachbegriffe verwendet.
Datenmatrix, wobei jede Zeile ein Vektor vorverarbeiteter Daten ist (zentriert und richtig normalisiert), die Anzahl der Zeilen m ist (die Anzahl der Datenvektoren), die Anzahl der Spalten n ist (die Dimension des Datenraums);
Matrix laden(Ladevorgänge), wobei jede Spalte ein Hauptkomponentenvektor ist, die Anzahl der Zeilen n ist (Datenraumdimension), die Anzahl der Spalten k ist (die Anzahl der für die Projektion ausgewählten Hauptkomponentenvektoren);
Abrechnungsmatrix(Ergebnisse)
wobei jede Zeile die Projektion des Datenvektors auf k Hauptkomponenten ist; Anzahl von Reihen – m (Anzahl von Datenvektoren), Anzahl von Spalten – k (Anzahl von für die Projektion ausgewählten Hauptkomponentenvektoren);
Z-Score-Matrix(Z-Werte)

wobei jede Zeile die Projektion des Datenvektors auf die k Hauptkomponenten ist, normalisiert auf die Einheits-Stichprobenvarianz; Anzahl von Reihen – m (Anzahl von Datenvektoren), Anzahl von Spalten – k (Anzahl von für die Projektion ausgewählten Hauptkomponentenvektoren);
Fehlermatrix (Reste) (Fehler oder Residuen)
Grundformel:
Damit ist die Hauptkomponentenmethode eine der Hauptmethoden der mathematischen Statistik. Sein Hauptzweck besteht darin, zwischen der Notwendigkeit, Datenarrays zu untersuchen, und einem Minimum an ihrer Verwendung zu unterscheiden.
Um das Studiengebiet genau zu beschreiben, wählen Analysten oft eine große Anzahl unabhängiger Variablen (p) aus. In diesem Fall kann ein schwerwiegender Fehler auftreten: Mehrere beschreibende Variablen können dieselbe Seite der abhängigen Variablen charakterisieren und dadurch stark miteinander korrelieren. Die Multikollinearität unabhängiger Variablen verzerrt die Ergebnisse der Studie erheblich und sollte daher eliminiert werden.
Die Hauptkomponentenanalyse (als vereinfachtes Modell der Faktorenanalyse, da bei dieser Methode keine Einzelfaktoren verwendet werden, die nur eine Variable x i beschreiben) ermöglicht es, den Einfluss hochkorrelierter Variablen zu einem Faktor zusammenzufassen, der die abhängige Variable von einer Seite charakterisiert. Als Ergebnis der Analyse, die mit der Methode der Hauptkomponenten durchgeführt wird, erreichen wir eine Komprimierung der Informationen auf die erforderliche Größe, die Beschreibung der abhängigen Variablen m (m Zuerst müssen Sie entscheiden, wie viele Faktoren Sie in dieser Studie hervorheben möchten. Im Rahmen der Methode der Hauptkomponenten beschreibt der erste Hauptfaktor den größten Prozentsatz der Varianz unabhängiger Variablen, dann in absteigender Reihenfolge. Somit erklärt jede nächste sequentiell identifizierte Hauptkomponente einen immer geringeren Anteil an der Variabilität der Faktoren x i . Die Aufgabe des Forschers besteht darin, festzustellen, wann die Variabilität wirklich klein und zufällig wird. Mit anderen Worten, wie viele Hauptkomponenten sollten für die weitere Analyse ausgewählt werden. Es gibt mehrere Methoden zur rationalen Auswahl der erforderlichen Anzahl von Faktoren. Das am häufigsten verwendete davon ist das Kaiser-Kriterium. Nach diesem Kriterium werden nur diejenigen Faktoren ausgewählt, deren Eigenwerte größer als 1 sind, also wird ein Faktor, der die Varianz nicht erklärt, gleich mindestens der Varianz einer Variablen weggelassen. Lassen Sie uns die in SPSS erstellte Tabelle 19 analysieren: Tabelle 19. Erklärte Gesamtvarianz Wie aus Tabelle 19 ersichtlich ist, sind in dieser Studie die Variablen x i hochgradig miteinander korreliert (dies wurde auch schon früher identifiziert und ist aus Tabelle 5 „Paarkorrelationskoeffizienten“ ersichtlich) und charakterisieren daher die abhängige Variable Y nahezu auf Einerseits: Die erste Hauptkomponente erklärt zunächst 90,7 % der Varianz x i , und nur der der ersten Hauptkomponente entsprechende Eigenwert ist größer als 1. Das ist natürlich ein Manko der Datenselektion, aber dieses Manko war bei der Auswahl selbst nicht ersichtlich. Die Analyse im SPSS-Paket ermöglicht es Ihnen, die Anzahl der Hauptkomponenten selbst zu wählen. Wählen wir die Zahl 6 - gleich der Anzahl der unabhängigen Variablen. Die zweite Spalte von Tabelle 19 zeigt die Quadratsummen der Rotationslasten, aus diesen Ergebnissen schließen wir die Anzahl der Faktoren. Die den ersten beiden Hauptkomponenten entsprechenden Eigenwerte sind größer als 1 (55,246 % bzw. 38,396 %), daher wählen wir nach der Kaiser-Methode die 2 signifikantesten Hauptkomponenten aus. Die zweite Methode zur Auswahl der erforderlichen Anzahl von Faktoren ist das "Scree"-Kriterium. Nach dieser Methode werden die Eigenwerte in Form eines einfachen Diagramms dargestellt, und es wird eine Stelle im Diagramm gewählt, an der sich die Abnahme der Eigenwerte von links nach rechts so weit wie möglich verlangsamt: Abbildung 3. Scree-Kriterium Wie in Abbildung 3 zu sehen ist, verlangsamt sich die Abnahme der Eigenwerte bereits ab der zweiten Komponente, aber die konstante Abnahmerate (sehr klein) beginnt erst ab der dritten Komponente. Daher werden die ersten beiden Hauptkomponenten für die weitere Analyse ausgewählt. Diese Schlussfolgerung stimmt mit der Schlussfolgerung überein, die unter Verwendung des Kaiser-Verfahrens erhalten wurde. Somit werden die ersten beiden sequentiell erhaltenen Hauptkomponenten schließlich ausgewählt. Nach der Hervorhebung der Hauptkomponenten, die in der weiteren Analyse verwendet werden, ist es notwendig, die Korrelation der Ausgangsvariablen x i mit den erhaltenen Faktoren zu bestimmen und darauf basierend die Namen der Komponenten anzugeben. Zur Analyse verwenden wir die Matrix der Faktorladungen A, deren Elemente die Korrelationskoeffizienten der Faktoren mit den ursprünglichen unabhängigen Variablen sind: Tabelle 20. Faktorladungsmatrix In diesem Fall ist die Interpretation der Korrelationskoeffizienten schwierig, daher ist es ziemlich schwierig, die ersten beiden Hauptkomponenten zu benennen. Daher verwenden wir weiterhin die Methode der orthogonalen Rotation des Varimax-Koordinatensystems, deren Zweck darin besteht, Faktoren so zu drehen, dass die einfachste Faktorstruktur für die Interpretation ausgewählt wird: Tabelle 21. Interpretationskoeffizienten Tabelle 21 zeigt, dass die erste Hauptkomponente am stärksten mit den Variablen x1, x2, x3 assoziiert ist; und die zweite - mit den Variablen x4, x5, x6. Daraus lässt sich also schließen Investitionsvolumen in Sachanlagen in der Region (Variable Y) hängt von zwei Faktoren ab: - das Volumen der von den Unternehmen der Region für den Zeitraum erhaltenen Eigen- und Fremdmittel (erste Komponente, z1); -
sowie von der Investitionsintensität der Unternehmen in der Region in Finanzanlagen und der Höhe des ausländischen Kapitals in der Region (zweite Komponente, z2). Abbildung 4. Streudiagramm Dieses Diagramm zeigt enttäuschende Ergebnisse. Ganz am Anfang der Studie haben wir versucht, die Daten so auszuwählen, dass die resultierende Variable Y normalverteilt ist, und das ist uns praktisch gelungen. Die Gesetze der Verteilung unabhängiger Variablen waren ziemlich weit von der Normalität entfernt, aber wir haben versucht, sie so nahe wie möglich zu bringen normales Gesetz(Daten entsprechend auswählen). Abbildung 4 zeigt, dass die anfängliche Hypothese über die Nähe des Verteilungsgesetzes unabhängiger Variablen zum Normalgesetz nicht bestätigt wird: Die Form der Wolke sollte einer Ellipse ähneln, in der Mitte sollten die Objekte dichter liegen als an den Rändern. Es ist erwähnenswert, dass die Erstellung einer multivariaten Stichprobe, in der alle Variablen gemäß dem Normalgesetz verteilt sind, eine Aufgabe ist, die mit großen Schwierigkeiten zu bewältigen ist (außerdem hat sie nicht immer eine Lösung). Dieses Ziel muss jedoch angestrebt werden: Dann sind die Ergebnisse der Analyse aussagekräftiger und verständlicher in der Interpretation. Leider ist es in unserem Fall, wenn die meiste Arbeit an der Analyse der gesammelten Daten erledigt ist, ziemlich schwierig, die Probe zu ändern. In späteren Arbeiten lohnt es sich jedoch, die Auswahl unabhängiger Variablen ernsthafter anzugehen und das Gesetz ihrer Verteilung so nah wie möglich an den Normalzustand heranzuführen. Die letzte Stufe der Hauptkomponentenanalyse ist die Konstruktion einer Regressionsgleichung für Hauptkomponenten (in diesem Fall für die erste und zweite Hauptkomponente). Mit SPSS berechnen wir die Parameter des Regressionsmodells: Tabelle 22. Parameter der Hauptkomponenten-Regressionsgleichung Die Regressionsgleichung hat die Form: y=47414,184 + 0,916*z1+0,213*z2, (b0) (b1) (b2) dann. b0=47 414,184
zeigt den Schnittpunkt der direkten Regression mit der Achse des resultierenden Indikators; b1= 0,916 – bei einer Erhöhung des Werts des Faktors z1 um 1 steigt der erwartete Durchschnittswert der Investitionssumme in das Anlagevermögen um 0,916; b2= 0,213 - bei einer erhöhung des werts des faktors z2 um 1 steigt der erwartete durchschnittliche wert der investitionssumme in das anlagevermögen um 0,213. In diesem Fall ist der Wert tcr ("alpha" = 0,001, "nu" = 53) = 3,46 kleiner als tobs für alle "beta"-Koeffizienten. Daher sind alle Koeffizienten signifikant. Tabelle 24. Qualität des Hauptkomponenten-Regressionsmodells Tabelle 24 gibt die Indikatoren wieder, die die Qualität des konstruierten Modells charakterisieren, nämlich: R – multipler Korrelationskoeffizient – gibt an, welcher Anteil der Y-Varianz durch die Z-Variation erklärt wird; R ^ 2 - die Bestimmungsmenge - zeigt den Anteil der erklärten Varianz der Abweichungen Y von ihrem Mittelwert. Der Standardfehler der Schätzung charakterisiert den Fehler des konstruierten Modells. Vergleichen wir diese Indikatoren mit denen des Potenzgesetz-Regressionsmodells (seine Qualität erwies sich als höher als die Qualität des linearen Modells, also vergleichen wir es mit dem Potenzgesetz-Modell): Tabelle 25. Quality-of-Power-Regressionsmodell So sind der multiple Korrelationskoeffizient R und der Determinationskoeffizient R^2 im Powermodell etwas höher als im Hauptkomponentenmodell. Außerdem ist der Standardfehler des Hauptkomponentenmodells VIEL höher als der des Potenzmodells. Daher ist die Qualität eines Potenzgesetz-Regressionsmodells höher als die eines Regressionsmodells, das auf Hauptkomponenten basiert. Lassen Sie uns das Regressionsmodell der Hauptkomponenten überprüfen, d. h. seine Signifikanz analysieren. Lassen Sie uns die Hypothese über die Bedeutungslosigkeit des Modells überprüfen, berechnen Sie F(obs.) = 204,784 (berechnet in SPSS), F(crit) (0,001; 2; 53) = 7,76. F(obs)>F(crit), daher wird die Hypothese über die Bedeutungslosigkeit des Modells verworfen. Das Modell ist bedeutsam. Als Ergebnis der Komponentenanalyse wurde also festgestellt, dass von den ausgewählten unabhängigen Variablen x i 2 Hauptkomponenten unterschieden werden können – z1 und z2, und z1 wird stärker von den Variablen x1, x2, x3 und z2 beeinflusst – durch x4, x5, x6 . Die auf den Hauptkomponenten aufgebaute Regressionsgleichung erwies sich als signifikant, obwohl sie der Potenzregressionsgleichung qualitativ unterlegen ist. Gemäß der Hauptkomponenten-Regressionsgleichung ist Y sowohl von Z1 als auch von Z2 positiv abhängig. Die anfängliche Multikollinearität der Variablen xi und die Tatsache, dass sie nicht gemäß dem Normalverteilungsgesetz verteilt sind, können jedoch die Ergebnisse des konstruierten Modells verzerren und es weniger aussagekräftig machen. Clusteranalyse Die nächste Stufe dieser Studie ist die Clusteranalyse. Die Aufgabe der Clusteranalyse besteht darin, die ausgewählten Regionen (n=56) aufgrund ihrer natürlichen Nähe in Bezug auf die Werte der Variablen x i in eine relativ kleine Anzahl von Gruppen (Cluster) einzuteilen. Bei der Durchführung von Clusteranalysen gehen wir davon aus, dass die geometrische Nähe von zwei oder mehr Punkten im Raum die physische Nähe der entsprechenden Objekte, ihre Homogenität (in unserem Fall die Homogenität von Regionen in Bezug auf Indikatoren, die sich auf Investitionen in das Anlagevermögen auswirken) bedeutet. In der ersten Stufe der Clusteranalyse ist es notwendig, die optimale Anzahl der zugeordneten Cluster zu bestimmen. Dazu ist es notwendig, ein hierarchisches Clustering durchzuführen - die sequentielle Zusammenfassung von Objekten zu Clustern, bis zwei große Cluster übrig bleiben, die sich im maximalen Abstand voneinander zu einem vereinigen. Das Ergebnis der hierarchischen Analyse (Rückschluss auf die optimale Anzahl von Clustern) hängt von der Methode ab, mit der der Abstand zwischen Clustern berechnet wird. Daher werden wir verschiedene Methoden testen und die entsprechenden Schlussfolgerungen ziehen. Nearest-Neighbour-Methode Wenn wir den Abstand zwischen einzelnen Objekten auf eine einzige Weise berechnen – als einfachen euklidischen Abstand –, wird der Abstand zwischen Clustern mit unterschiedlichen Methoden berechnet. Nach der Nearest-Neighbour-Methode entspricht der Abstand zwischen Clustern dem Mindestabstand zwischen zwei Objekten unterschiedlicher Cluster. Die Analyse im SPSS-Paket geht wie folgt vor. Zuerst wird die Abstandsmatrix zwischen allen Objekten berechnet und dann werden die Objekte basierend auf der Abstandsmatrix sequentiell zu Clustern zusammengefasst (für jeden Schritt wird die Matrix neu erstellt). Die Schritte der sequentiellen Zusammenführung sind in der Tabelle dargestellt: Tabelle 26 Agglomerationsschritte. Nearest-Neighbour-Methode Wie aus Tabelle 26 ersichtlich, wurden in der ersten Stufe die Elemente 7 und 8 kombiniert, da der Abstand zwischen ihnen minimal war - 0,003. Außerdem nimmt der Abstand zwischen den zusammengeführten Objekten zu. Die Tabelle zeigt auch die optimale Anzahl von Clustern. Dazu müssen Sie darauf achten, bei welchem Schritt der Abstandswert stark sprunghaft ist, und die Anzahl dieser Ansammlungen von der Anzahl der untersuchten Objekte subtrahieren. In unserem Fall: (56-53)=3 ist die optimale Anzahl von Clustern. Abbildung 5. Dendrogramm. Nearest-Neighbor-Methode Eine ähnliche Schlussfolgerung über die optimale Anzahl von Clustern kann durch Betrachten des Dendrogramms (Abb. 5) gezogen werden: 3 Cluster sollten ausgewählt werden, und der erste Cluster enthält Objekte mit den Nummern 1-54 (insgesamt 54 Objekte) und der zweite und dritte Cluster - jeweils ein Objekt (mit 55 bzw. 56 nummeriert). Dieses Ergebnis deutet darauf hin, dass die ersten 54 Regionen in Bezug auf die Indikatoren für Investitionen in das Anlagevermögen relativ homogen sind, während sich die Objekte mit der Nummer 55 (Republik Dagestan) und 56 (Region Nowosibirsk) deutlich vom allgemeinen Hintergrund abheben. Es ist erwähnenswert, dass diese Unternehmen unter allen ausgewählten Regionen das größte Volumen an Investitionen in Sachanlagen haben. Diese Tatsache belegt einmal mehr die hohe Abhängigkeit der resultierenden Variablen (Investitionsvolumen) von den gewählten unabhängigen Variablen. Ähnliche Überlegungen werden für andere Verfahren zum Berechnen des Abstands zwischen Clustern durchgeführt. Methode des fernen Nachbarn Tabelle 27 Agglomerationsschritte. Methode des fernen Nachbarn Bei der Far-Neighbour-Methode wird der Abstand zwischen Clustern als der maximale Abstand zwischen zwei Objekten in zwei verschiedenen Clustern berechnet. Gemäß Tabelle 27 ist die optimale Anzahl von Clustern (56-53)=3. Abbildung 6. Dendrogramm. Methode des fernen Nachbarn Gemäß dem Dendrogramm wäre die optimale Lösung auch die Zuordnung von 3 Clustern: Der erste Cluster umfasst die Regionen mit den Nummern 1-50 (50 Regionen), der zweite die Nummern 51-55 (5 Regionen), der dritte die letzte Regionsnummer 56. Schwerpunktmethode Bei der "Schwerpunkt"-Methode wird der Abstand zwischen Clustern als der euklidische Abstand zwischen den "Schwerpunkt" von Clustern genommen - dem arithmetischen Mittel ihrer Indikatoren x i . Abbildung 7. Dendrogramm. Schwerpunktmethode Abbildung 7 zeigt, dass die optimale Anzahl von Clustern wie folgt ist: 1 Cluster – 1–47 Objekte; 2 Cluster - 48-54 Objekte (insgesamt 6); 3 Cluster - 55 Objekte; 4 Cluster - 56 Objekte. Das Prinzip der „durchschnittlichen Verbindung“ In diesem Fall ist der Abstand zwischen Clustern gleich dem Mittelwert der Abstände zwischen allen möglichen Beobachtungspaaren, wobei jeweils eine Beobachtung von einem Cluster und die zweite von einem anderen genommen wird. Die Analyse der Tabelle der Agglomerationsschritte zeigte, dass die optimale Anzahl von Clustern (56–52) = 4 ist. Vergleichen wir diese Schlussfolgerung mit der Schlussfolgerung aus der Analyse des Dendrogramms. Abbildung 8 zeigt, dass Cluster 1 Objekte mit den Nummern 1–50, Cluster 2 – Objekte 51–54 (4 Objekte), Cluster 3 – Region 55, Cluster 4 – Region 56 enthalten wird. Abbildung 8. Dendrogramm. Methode der "durchschnittlichen Verbindung"
ANWENDUNG DER HAUPTKOMPONENTEN-METHODE ZUR VERARBEITUNG MEHRDIMENSIONALER STATISTISCHER DATEN Berücksichtigt werden Fragen der Verarbeitung mehrdimensionaler statistischer Daten zur Bewertung von Schülern auf der Grundlage der Anwendung der Methode der Hauptkomponenten. Schlüsselwörter: Multivariate Datenanalyse, Dimensionsreduktion, Hauptkomponentenanalyse, Rating. In der Praxis trifft man häufig auf Situationen, in denen der Untersuchungsgegenstand durch eine Vielzahl von Parametern gekennzeichnet ist, die jeweils gemessen oder bewertet werden. Die Analyse des anfänglichen Datenfeldes, das als Ergebnis der Untersuchung mehrerer Objekte des gleichen Typs erhalten wird, ist eine praktisch unlösbare Aufgabe. Daher muss der Forscher die Verbindungen und Abhängigkeiten zwischen den Anfangsparametern analysieren, um einige von ihnen zu verwerfen oder sie durch eine kleinere Anzahl beliebiger Funktionen aus ihnen zu ersetzen, während möglichst alle darin enthaltenen Informationen erhalten bleiben. In diesem Zusammenhang stellen sich die Aufgaben der Dimensionsreduktion, d. h. der Übergang vom ursprünglichen Datenarray zu einer deutlich geringeren Anzahl von Indikatoren, die aus den ursprünglichen ausgewählt oder durch eine Transformation erhalten werden (mit dem geringsten Verlust an Informationen, die im ursprünglichen Array enthalten sind). ) und Klassifizierung - Trennung der betrachteten Sammlungen von Objekten in homogene (in gewissem Sinne) Gruppen. Wenn für eine große Anzahl heterogener und stochastisch miteinander verbundener Indikatoren die Ergebnisse einer statistischen Erhebung einer ganzen Reihe von Objekten erhalten wurden, sollte man zur Lösung der Probleme der Klassifizierung und Dimensionsreduktion die Werkzeuge der multivariaten statistischen Analyse verwenden, in insbesondere die Methode der Hauptkomponenten. Der Artikel schlägt eine Technik zur Anwendung der Hauptkomponentenmethode zur Verarbeitung multivariater statistischer Daten vor. Als Beispiel wird die Lösung des Problems der statistischen Verarbeitung multivariater Ergebnisse von Schülerbewertungen angegeben. 1.
Definition und Berechnung der Hauptkomponenten..png" height="22 src="> Merkmale. Als Ergebnis erhalten wir mehrdimensionale Beobachtungen, die jeweils als Vektorbeobachtung dargestellt werden können wobei https://pandia.ru/text/79/206/images/image005.png" height="22 src=">.png" height="22 src="> das Symbol für die Transpositionsoperation ist. Die resultierenden mehrdimensionalen Beobachtungen müssen statistisch verarbeitet werden..png" height="22 src=">.png" height="22 src=">.png" width="132" height="25 src=">.png" width ="33" height="22 src="> erlaubte Transformationen der untersuchten Features 0 " style="border-collapse:collapse"> ist die Normalisierungsbedingung; – Orthogonalitätsbedingung Erhalten durch eine ähnliche Transformation https://pandia.ru/text/79/206/images/image018.png" width="79" height="23 src="> und stellen die Hauptkomponenten dar. Von ihnen Variablen mit Minimum Varianz von der weiteren Analyse ausgeschlossen, d.h..png" width="131" height="22 src="> in der Transformation (2)..png" width="13" height="22 src="> dieser Matrix gleich den Varianzen der Hauptkomponenten sind. Daher ist die erste Hauptkomponente https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src="> eine solche normalisierte zentrierte lineare Kombination dieser Indikatoren , die unter allen anderen ähnlichen Kombinationen die höchste Streuung hat..png" width="12" height="22 src="> –
benutzerdefinierter Matrixvektor https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">.png" width="80" height="23 src= "> ist eine solche normalisierte zentrierte lineare Kombination dieser Indikatoren, die nicht mit https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src= korreliert ">. png" width="80" height="23 src="> in verschiedenen Einheiten gemessen werden, dann werden die Ergebnisse der Studie unter Verwendung der Hauptkomponenten erheblich von der Wahl des Maßstabs und der Art der Maßeinheiten abhängen , und die resultierenden linearen Kombinationen der ursprünglichen Variablen sind schwer zu interpretieren. Diesbezüglich mit unterschiedlichen Maßeinheiten der Anfangsmerkmale DIV_ADBLOCK310 ">
Komponente Anfängliche Eigenwerte Summe der quadrierten Rotationslasten
Gesamt % Dispersion Kumulativ % Gesamt % Dispersion Kumulativ %
Dimension0
5,442
90,700
90,700
3,315
55,246
55,246
,457
7,616
98,316
2,304
38,396
93,641
,082
1,372
99,688
,360
6,005
99,646
,009
,153
99,841
,011
,176
99,823
,007
,115
99,956
,006
,107
99,930
,003
,044
100,000
,004
,070
100,000
Extraktionsverfahren: Hauptkomponentenanalyse.
Matrixkomponenten a
Komponente
X1 ,956
-,273
,084
,037
-,049
,015
X2 ,986
-,138
,035
-,080
,006
,013
X3 ,963
-,260
,034
,031
,060
-,010
X4 ,977
,203
,052
-,009
-,023
-,040
X5 ,966
,016
-,258
,008
-,008
,002
X6 ,861
,504
,060
,018
,016
,023
Extraktionsverfahren: Hauptkomponentenanalyse.
a. Extrahierte Komponenten: 6
Matrix gedrehter Komponenten a
Komponente
X1 ,911
,384
,137
-,021
,055
,015
X2 ,841
,498
,190
,097
,000
,007
X3 ,900
,390
,183
-,016
-,058
-,002
X4 ,622
,761
,174
,022
,009
,060
X5 ,678
,564
,472
,007
,001
,005
X6 ,348
,927
,139
,001
-,004
-,016
Extraktionsverfahren: Hauptkomponentenanalyse. Rotationsverfahren: Varimax mit Kaiser-Normalisierung.
a. Die Rotation konvergierte in 4 Iterationen.

Modell Nicht-Standardisierte Koeffizienten Standardisierte Koeffizienten t Wert
B Std. Fehler Beta
(Konstante) 47414,184
1354,505
35,005
,001
Z1 26940,937
1366,763
,916
19,711
,001
Z2 6267,159
1366,763
,213
4,585
,001
Modell R R Quadrat Bereinigtes R-Quadrat Std. Schätzfehler
Dimension0
.941a ,885
,881
10136,18468
a. Prädiktoren: (konst.) Z1, Z2
b. Abhängige Variable: Y
Bühne Cluster zusammengeführt mit Chancen Nächste Stufe
Cluster 1 Cluster 2 Cluster 1 Cluster 2
,003
,004
,004
,005
,005
,005
,005
,006
,007
,007
,009
,010
,010
,010
,010
,011
,012
,012
,012
,012
,012
,013
,014
,014
,014
,014
,015
,015
,016
,017
,018
,018
,019
,019
,020
,021
,021
,022
,024
,025
,027
,030
,033
,034
,042
,052
,074
,101
,103
,126
,163
,198
,208
,583
1,072

Bühne Cluster zusammengeführt mit Chancen Phase des ersten Auftretens des Clusters Nächste Stufe
Cluster 1 Cluster 2 Cluster 1 Cluster 2
,003
,004
,004
,005
,005
,005
,005
,007
,009
,010
,010
,011
,011
,012
,012
,014
,014
,014
,017
,017
,018
,018
,019
,021
,022
,026
,026
,027
,034
,035
,035
,037
,037
,042
,044
,046
,063
,077
,082
,101
,105
,117
,126
,134
,142
,187
,265
,269
,275
,439
,504
,794
,902
1,673
2,449




![]()
https://pandia.ru/text/79/206/images/image030.png" width="17" height="22 src=">.png" width="56" height="23 src=">. Nach einer solchen Transformation werden die Hauptkomponenten relativ zu den Werten https://pandia.ru/text/79/206/images/image033.png" width="17" height="22 src="> analysiert , das ist auch eine Korrelationsmatrix https://pandia.ru/text/79/206/images/image035.png" width="162" height="22 src=">.png" width="13" height=" 22 src="> bis ich- Das Quellmerkmal ..png" width="14" height="22 src=">.png" width="10" height="22 src="> ist gleich der Varianz v- Hauptkomponentehttps://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> werden bei der sinnvollen Interpretation der Hauptkomponenten ..png" width verwendet ="20" Höhe="22 Quelle=">.png" Breite="251" Höhe="25 Quelle=">
Um Berechnungen durchzuführen, werden Vektorbeobachtungen in einer Mustermatrix aggregiert, in der die Zeilen den kontrollierten Merkmalen und die Spalten den Untersuchungsobjekten entsprechen (die Dimension der Matrix ist https://pandia.ru/ text/79/206/images/image043.png" width="348"height="67 src=">
Nachdem wir die Anfangsdaten zentriert haben, finden wir die Probenkorrelationsmatrix unter Verwendung der Formel
https://pandia.ru/text/79/206/images/image045.png" width="204" height="69 src=">
Diagonale Matrixelemente https://pandia.ru/text/79/206/images/image047.png" width="206" height="68 src=">
Die Elemente außerhalb der Diagonale dieser Matrix sind Stichprobenschätzungen der Korrelationskoeffizienten zwischen dem entsprechenden Merkmalspaar.
Stellen Sie die charakteristische Gleichung für Matrix 0 auf " style="margin-left:5.4pt;border-collapse:collapse">

Finden Sie alle seine Wurzeln:
Um nun die Komponenten der Hauptvektoren zu finden, ersetzen wir nacheinander numerische Werte https://pandia.ru/text/79/206/images/image065.png" width="16" height="22 src=" >.png" width="102 "height="24 src=">
Zum Beispiel mit https://pandia.ru/text/79/206/images/image069.png" width="262" height="70 src=">
Es ist offensichtlich, dass das resultierende Gleichungssystem aufgrund der Homogenität konsistent und indefinit ist, d.h. es hat eine unendliche Menge von Lösungen. Um die einzige für uns interessante Lösung zu finden, verwenden wir die folgenden Bestimmungen:
1. Für die Wurzeln des Systems kann die Relation geschrieben werden
https://pandia.ru/text/79/206/images/image071.png" width="20" height="23 src="> – algebraische Addition j-tes Element von jedem ich Zeile der Systemmatrix.
2. Das Vorhandensein der Normierungsbedingung (2) sichert die Eindeutigkeit der Lösung des betrachteten Gleichungssystems..png" width="13" height="22 src=">, außer dass alle eindeutig bestimmt sind können gleichzeitig das Vorzeichen wechseln, jedoch spielen die Vorzeichen der Komponenten-Eigenvektoren keine wesentliche Rolle, da ihre Änderung das Ergebnis der Analyse nicht beeinflusst, sie können nur dazu dienen, gegensätzliche Trends auf der entsprechenden Hauptkomponente anzuzeigen.
So erhalten wir unseren eigenen Vektor https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">:
https://pandia.ru/text/79/206/images/image024.png" width="12" height="22 src="> auf Gleichheit prüfen
https://pandia.ru/text/79/206/images/image076.png" width="503" height="22">
… … … … … … … … …
https://pandia.ru/text/79/206/images/image078.png" width="595" height="22 src=">
https://pandia.ru/text/79/206/images/image080.png" width="589" height="22 src=">
wo https://pandia.ru/text/79/206/images/image082.png" width="16" height="22 src=">.png" width="23" height="22 src="> sind die normierten Werte der entsprechenden Anfangsmerkmale.
Erstellen Sie eine orthogonale lineare Transformationsmatrix https://pandia.ru/text/79/206/images/image086.png" width="94" height="22 src=">
Da gemäß den Eigenschaften der Hauptkomponenten die Summe der Varianzen der Anfangsmerkmale gleich der Summe der Varianzen aller Hauptkomponenten ist, haben wir unter Berücksichtigung der Tatsache, dass wir normalisierte Anfangsmerkmale betrachtet haben können abschätzen, welcher Teil der Gesamtvariabilität der Anfangsmerkmale jede der Hauptkomponenten erklärt. Zum Beispiel haben wir für die ersten beiden Hauptkomponenten:
|
|
Somit erklären die ersten sieben Hauptkomponenten gemäß dem für die aus der Korrelationsmatrix gefundenen Hauptkomponenten verwendeten Informativitätskriterium 88,97 % der Gesamtvariabilität der fünfzehn Anfangsmerkmale.
Verwenden der linearen Transformationsmatrix https://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> (für die ersten sieben Hauptkomponenten):
https://pandia.ru/text/79/206/images/image090.png" width="16" height="22 src="> - die Anzahl der Diplome, die im Wettbewerb für wissenschaftliche Arbeiten und Abschlussarbeiten erhalten wurden; https:/ /pandia .ru/text/79/206/images/image092.png" width="16" height="22 src=">.png" width="22" height="22 src=">.png" width =" 22" height="22 src=">.png" width="22" height="22 src="> – Auszeichnungen und Preise bei regionalen, regionalen und städtischen Sportwettbewerben.
3..png" width="16" height="22 src=">(Anzahl der Zertifikate basierend auf den Ergebnissen der Teilnahme an Wettbewerben für wissenschaftliche und Diplomarbeiten).
4..png" width="22" height="22 src=">(Auszeichnungen und Preise bei Universitätswettbewerben).
6. Die sechste Hauptkomponente ist positiv korreliert mit DIV_ADBLOCK311">
4. Die dritte Hauptkomponente ist die Aktivität der Schüler im Bildungsprozess.
5. Die vierte und sechste Komponente sind der studentische Fleiß während des Frühjahrs- bzw. Herbstsemesters.
6. Die fünfte Hauptkomponente ist der Grad der Teilnahme an Wettbewerben des Hochschulsports.
Um in Zukunft alle notwendigen Berechnungen bei der Identifizierung der Hauptkomponenten durchzuführen, wird vorgeschlagen, spezialisierte statistische Softwaresysteme wie STATISTICA zu verwenden, die den Analyseprozess erheblich erleichtern werden.
Das in diesem Beitrag am Beispiel der Notenfeststellung von Studierenden beschriebene Verfahren zur Ermittlung der Hauptbestandteile wird für Bachelor- und Masterzeugnisse vorgeschlagen.
REFERENZLISTE
1. Angewandte Statistik: Klassifikation und Dimensionsreduktion: Ref.-Nr. ed. / , ; ed. . - M.: Finanzen und Statistik, 1989. - 607 p.
2. Handbuch der angewandten Statistik: in 2 Bänden: [per. aus dem Englischen] / Hrsg. E. Lloyd, W. Ledermann, . - M.: Finanzen und Statistik, 1990. - T. 2. - 526 p.
3. Angewandte Statistik. Grundlagen der Ökonometrie. In 2 Bänden T.1. Wahrscheinlichkeitstheorie u angewendete Statistiken: Studien. für Universitäten / , V. S. Mkhitaryan. - 2. Aufl., Rev. - M: UNITY-DANA, 2001. - 656 p.
4. Afifi, A. Statistische Analyse: ein computergestützter Ansatz: [transl. aus dem Englischen] / A. Afifi, S. Eisen.- M.: Mir, 1982. - 488 p.
5. Dronov, statistische Analyse: Lehrbuch. Beihilfe / . -Barna 3. – 213 S.
6. Anderson, T. Einführung in die multivariate statistische Analyse / T. Anderson; pro. aus dem Englischen. [usw.]; ed. . - M.: Zustand. Verlag für Phys.-Math. lit., 1963. - 500 S.
7. Lawley, D. Faktorenanalyse als statistische Methode / D. Lawley, A. Maxwell; pro. aus dem Englischen. . – M.: Mir, 1967. – 144 S.
8. Dubrov, statistische Methoden: Lehrbuch /,. - M.: Finanzen und Statistik, 2003. - 352 p.
9. Kendall, M. Multivariate statistische Analyse und Zeitreihen / M. Kendall, A. Stuart;per. aus dem Englischen. , ; ed. , . – M.: Nauka, 1976. – 736 S.
10. Beloglazov, Analyse in Problemen der Qualimetrie der Bildung, Izv. RAN. Theorie und Kontrollsysteme. - 2006. - Nr. 6. - S. 39 - 52.
Das Material ging am 8. November 2011 bei der Redaktion ein.
Die Arbeiten wurden im Rahmen des föderalen Zielprogramms „Wissenschaftliches und wissenschaftlich-pädagogisches Personal des innovativen Russlands“ für 2009-2013 durchgeführt. (Staatsvertrag Nr. P770).
Hauptkomponentenmethode
Hauptkomponentenmethode(Englisch) Hauptkomponentenanalyse, PCA ) ist eine der wichtigsten Methoden, um die Dimensionalität von Daten zu reduzieren und so die geringste Menge an Informationen zu verlieren. Erfunden von K. Pearson (Eng. Karl Pearson ) in d. Es wird in vielen Bereichen verwendet, wie Mustererkennung, Computer Vision, Datenkomprimierung usw. Die Berechnung von Hauptkomponenten wird auf die Berechnung von Eigenvektoren und Eigenwerten der Kovarianzmatrix der Originaldaten reduziert. Manchmal wird die Hauptkomponentenmethode aufgerufen Karhunen-Loeve-Transformation(Englisch) Karhunen-Loeve) oder die Hotelling-Transformation (engl. Hotelling verwandeln). Andere Möglichkeiten zur Reduzierung der Datendimension sind die Methode der unabhängigen Komponenten, die mehrdimensionale Skalierung sowie zahlreiche nichtlineare Verallgemeinerungen: die Methode der Hauptkurven und Mannigfaltigkeiten, die Methode der elastischen Abbildungen, die Suche nach der besten Projektion (engl. Projektionsverfolgung), neuronale Netzwerkmethoden des "Engpasses" usw.
Formelle Erklärung des Problems
Das Problem der Hauptkomponentenanalyse hat mindestens vier grundlegende Versionen:
- angenäherte Daten durch lineare Mannigfaltigkeiten niedrigerer Dimension;
- finden Sie Unterräume niedrigerer Dimension in der orthogonalen Projektion, auf denen die Datenstreuung (dh die Standardabweichung vom Mittelwert) maximal ist;
- finden Sie Unterräume niedrigerer Dimension in der orthogonalen Projektion, auf denen der quadratische Mittelwertabstand zwischen Punkten maximal ist;
- für eine gegebene mehrdimensionale Zufallsvariable eine solche orthogonale Koordinatentransformation konstruieren, dass dadurch die Korrelationen zwischen einzelnen Koordinaten verschwinden.
Die ersten drei Versionen arbeiten mit endlichen Datensätzen. Sie sind gleichwertig und verwenden keine Hypothesen zur statistischen Datengenerierung. Die vierte Version arbeitet mit Zufallsvariablen. Endliche Mengen erscheinen hier als Stichproben aus einer gegebenen Verteilung und Lösung von drei der ersten Probleme - als Annäherung an die "wahre" Karhunen-Loeve-Transformation. Dies wirft eine zusätzliche und nicht ganz triviale Frage nach der Genauigkeit dieser Näherung auf.
Approximation von Daten durch lineare Mannigfaltigkeiten
Illustration zum berühmten Werk von K. Pearson (1901): Angegeben sind Punkte auf einer Ebene, - der Abstand von zu einer Geraden. Suche nach einer geraden Linie, die die Summe minimiert
Die Methode der Hauptkomponenten begann mit dem Problem der besten Approximation einer endlichen Menge von Punkten durch Geraden und Ebenen (K. Pearson, 1901). Gegeben sei eine endliche Menge von Vektoren. Für jede unter allen -dimensionalen linearen Mannigfaltigkeiten finden Sie so, dass die Summe der quadrierten Abweichungen von minimal ist:
,wo ist der euklidische Abstand von einem Punkt zu einer linearen Mannigfaltigkeit. Jede -dimensionale lineare Mannigfaltigkeit in kann als Satz von Linearkombinationen definiert werden, bei denen die Parameter über die reelle Linie laufen, und ist ein orthonormaler Satz von Vektoren
,wo ist die euklidische Norm, ist das euklidische Skalarprodukt oder in Koordinatenform:
.Die Lösung des Approximationsproblems für ist durch eine Menge verschachtelter linearer Mannigfaltigkeiten , gegeben. Diese linearen Mannigfaltigkeiten werden durch einen orthonormalen Satz von Vektoren (Hauptkomponentenvektoren) und einen Vektor definiert. Der Vektor wird als Lösung des Minimierungsproblems für gesucht:
.Hauptkomponentenvektoren können als Lösungen für gleichartige Optimierungsprobleme gefunden werden:
1) Daten zentralisieren (Durchschnitt abziehen): . Jetzt ; 2) finde die erste Hauptkomponente als Lösung des Problems; . Wenn die Lösung nicht eindeutig ist, wählen Sie eine davon aus. 3) Subtrahiere von den Daten die Projektion auf die erste Hauptkomponente: ; 4) finde die zweite Hauptkomponente als Lösung des Problems . Wenn die Lösung nicht eindeutig ist, wählen Sie eine davon aus. … 2k-1) Subtrahieren Sie die Projektion auf die -te Hauptkomponente (denken Sie daran, dass die Projektionen auf die vorherigen Hauptkomponenten bereits subtrahiert wurden): ; 2k) Finde die k-te Hauptkomponente als Lösung des Problems: . Wenn die Lösung nicht eindeutig ist, wählen Sie eine davon aus. …
Bei jedem vorbereitenden Schritt subtrahieren wir die Projektion auf die vorherige Hauptkomponente. Die gefundenen Vektoren sind einfach als Ergebnis der Lösung des beschriebenen Optimierungsproblems orthonormal, um jedoch zu verhindern, dass Berechnungsfehler die gegenseitige Orthogonalität der Hauptkomponentenvektoren verletzen, können sie in die Bedingungen des Optimierungsproblems aufgenommen werden.
Die Nichteindeutigkeit in der Definition, neben der trivialen Willkür in der Vorzeichenwahl (und Lösung des gleichen Problems), kann bedeutsamer sein und beispielsweise aus Datensymmetriebedingungen herrühren. Die letzte Hauptkomponente ist ein Einheitsvektor, der zu allen vorherigen orthogonal ist.
Suchen Sie nach orthogonalen Projektionen mit der größten Streuung

Die erste Hauptkomponente maximiert die Stichprobenvarianz der Datenprojektion
Gegeben sei ein zentrierter Satz von Datenvektoren (das arithmetische Mittel ist Null). Die Aufgabe besteht darin, eine solche orthogonale Transformation zu einem neuen Koordinatensystem zu finden, für die folgende Bedingungen gelten würden:
Die Singulärwertzerlegungstheorie wurde von J. J. Sylvester (Eng. James Joseph Silvester ) in d. und ist insgesamt dargelegt detaillierte Anleitungen zur Matrizentheorie.
Ein einfacher iterativer Singulärwert-Zerlegungsalgorithmus
Das Hauptverfahren ist die Suche nach der besten Annäherung einer beliebigen Matrix durch eine Matrix der Form (wobei ein Dimensionsvektor ist und ein Dimensionsvektor ist) nach der Methode der kleinsten Quadrate:
Die Lösung dieses Problems wird durch aufeinanderfolgende Iterationen unter Verwendung expliziter Formeln gegeben. Für einen festen Vektor werden die Werte, die das Minimum für das Formular liefern, eindeutig und explizit aus den Gleichheiten bestimmt:
In ähnlicher Weise werden für einen festen Vektor die folgenden Werte bestimmt:
Als erste Näherung des Vektors nehmen wir einen zufälligen Vektor der Einheitslänge, berechnen den Vektor , berechnen dann den Vektor für diesen Vektor usw. Jeder Schritt verringert den Wert von . Als Abbruchkriterium wird die Kleinheit der relativen Abnahme des Werts des minimierten Funktionals pro Iterationsschritt () oder die Kleinheit des Werts selbst verwendet.
Als Ergebnis erhielten wir für die Matrix die beste Annäherung durch eine Matrix der Form (hier bezeichnet der hochgestellte Index die Annäherungszahl). Weiterhin subtrahieren wir die resultierende Matrix von der Matrix und suchen für die erhaltene Abweichungsmatrix wieder nach der besten Näherung des gleichen Typs, und so weiter, bis beispielsweise die Norm hinreichend klein wird. Als Ergebnis haben wir ein iteratives Verfahren zur Zerlegung einer Matrix als Summe von Matrizen vom Rang 1 erhalten, also . Wir nehmen die Vektoren an und normieren sie: Als Ergebnis erhält man eine Annäherung von singulären Zahlen und singulären Vektoren (rechts - und links - ).
Die Vorteile dieses Algorithmus liegen in seiner außergewöhnlichen Einfachheit und der Möglichkeit, ihn nahezu unverändert auf Daten mit Lücken sowie gewichtete Daten zu übertragen.
Es gibt verschiedene Modifikationen des Basisalgorithmus, die die Genauigkeit und Stabilität verbessern. Beispielsweise sollten die Vektoren der Hauptkomponenten für verschiedene „konstruktiv“ orthogonal sein, jedoch summieren sich bei einer großen Anzahl von Iterationen (große Dimension, viele Komponenten) kleine Abweichungen von der Orthogonalität und es kann jeweils eine spezielle Korrektur erforderlich sein Schritt, wobei seine Orthogonalität zu den zuvor gefundenen Hauptkomponenten sichergestellt wird.
Singulärwertzerlegung von Tensoren und Tensorhauptkomponentenmethode
Oft hat ein Datenvektor zusätzlich die Struktur einer rechteckigen Tabelle (z. B. eines flachen Bildes) oder sogar einer mehrdimensionalen Tabelle – also eines Tensors : , . Auch in diesem Fall ist es effizient, die Singulärwertzerlegung zu verwenden. Die Definition, Grundformeln und Algorithmen werden praktisch unverändert übernommen: Anstelle einer Datenmatrix haben wir einen -Indexwert , wobei der erste Index die Datenpunkt-(Tensor-)Nummer ist.
Das Hauptverfahren ist die Suche nach der besten Annäherung des Tensors durch einen Tensor der Form (wobei - -dimensionaler Vektor ( - Anzahl der Datenpunkte), - Dimensionsvektor bei ) nach der Methode der kleinsten Quadrate:
Die Lösung dieses Problems wird durch aufeinanderfolgende Iterationen unter Verwendung expliziter Formeln gegeben. Sind alle Faktorvektoren bis auf einen gegeben, so wird dieser verbleibende explizit bestimmt aus ausreichende Voraussetzungen Minimum.
Als erste Annäherung von Vektoren () nehmen wir zufällige Vektoren der Einheitslänge, berechnen den Vektor, dann berechnen wir für diesen Vektor und diese Vektoren den Vektor usw. (Durchlaufen der Indizes) Jeder Schritt reduziert den Wert von . Der Algorithmus konvergiert offensichtlich. Als Abbruchkriterium wird die Kleinheit der relativen Abnahme des Werts des zu minimierenden Funktionals pro Zyklus oder die Kleinheit des Werts selbst verwendet. Weiterhin subtrahieren wir die resultierende Näherung vom Tensor und suchen für den Rest wieder die beste Näherung des gleichen Typs, und so weiter, bis beispielsweise die Norm des nächsten Rests hinreichend klein wird.
Diese Mehrkomponenten-Singulärwertzerlegung (Tensormethode der Hauptkomponenten) wird erfolgreich bei der Verarbeitung von Bildern, Videosignalen und im weiteren Sinne aller Daten verwendet, die eine Tabellen- oder Tensorstruktur aufweisen.
Transformationsmatrix zu Hauptkomponenten
Die Datentransformationsmatrix in Hauptkomponenten besteht aus Hauptkomponentenvektoren, die in absteigender Reihenfolge der Eigenwerte angeordnet sind:
(bedeutet transponieren),Das heißt, die Matrix ist orthogonal.
Die meisten Datenvariationen konzentrieren sich auf die ersten Koordinaten, was es Ihnen ermöglicht, sich in einen niedrigerdimensionalen Raum zu bewegen.
Restdispersion
Lassen Sie die Daten zentriert sein, . Wenn die Datenvektoren durch ihre Projektion auf die ersten Hauptkomponenten ersetzt werden, wird das mittlere Fehlerquadrat pro Datenvektor eingeführt:
wo sind die Eigenwerte der empirischen Kovarianzmatrix, angeordnet in absteigender Reihenfolge, unter Berücksichtigung der Multiplizität.
Dieser Wert wird aufgerufen Restdispersion. Wert
genannt erklärte Varianz. Ihre Summe ist gleich der Stichprobenvarianz. Der entsprechende quadrierte relative Fehler ist das Verhältnis der Restvarianz zur Stichprobenvarianz (d. h. Anteil der unerklärten Varianz):
Der relative Fehler bewertet die Anwendbarkeit der Hauptkomponentenmethode mit Projektion auf die ersten Komponenten.
Kommentar: In den meisten Rechenalgorithmen werden Eigenwerte mit den entsprechenden Eigenvektoren - Hauptkomponenten in der Reihenfolge "vom größten zum kleinsten" berechnet. Zur Berechnung reicht es aus, die ersten Eigenwerte und die Spur der empirischen Kovarianzmatrix (die Summe der Diagonalelemente, also der Varianzen entlang der Achsen) zu berechnen. Dann
Auswahl der Hauptkomponenten nach der Kaiser-Regel
Der Zielansatz, die Anzahl der Hauptkomponenten durch den geforderten Anteil der erklärten Varianz abzuschätzen, ist formal immer anwendbar, setzt aber implizit voraus, dass keine Trennung in „Signal“ und „Rauschen“ erfolgt und jede vorgegebene Genauigkeit sinnvoll ist. Daher ist oft eine andere Heuristik ergiebiger, basierend auf der Hypothese des Vorhandenseins eines „Signals“ (vergleichsweise kleine Dimension, relativ große Amplitude) und „Rauschen“ (große Dimension, relativ kleine Amplitude). So gesehen wirkt das Hauptkomponentenverfahren wie ein Filter: Das Signal ist hauptsächlich in der Projektion auf die ersten Hauptkomponenten enthalten, in den restlichen Komponenten ist der Rauschanteil deutlich höher.
Frage: Wie kann man die Anzahl der notwendigen Hauptkomponenten abschätzen, wenn das Signal-Rausch-Verhältnis nicht im Voraus bekannt ist?
Die einfachste und älteste Hauptkomponenten-Auswahlmethode gibt Kaisers Herrschaft(Englisch) Kaisers Herrschaft): Diese Hauptkomponenten sind für die von Bedeutung
das heißt, es übersteigt den Mittelwert (mittlere Stichprobenvarianz der Koordinaten des Datenvektors). Die Kaiser-Regel funktioniert gut in einfachen Fällen, in denen es mehrere Hauptkomponenten mit gibt, die viel größer als der Mittelwert sind, und der Rest der Eigenwerte kleiner als er ist. In komplexeren Fällen kann es zu viele signifikante Hauptkomponenten geben. Normalisiert man die Daten entlang der Achsen auf Einheitsstichprobenvarianz, dann nimmt die Kaiser-Regel eine besonders einfache Form an: Nur die Hauptkomponenten sind für welche signifikant
Schätzung der Anzahl der Hauptkomponenten mit der Broken Cane Rule

Beispiel: Abschätzen der Anzahl der Hauptkomponenten nach der Rohrbruchregel in Dimension 5.
Einer der beliebtesten heuristischen Ansätze zum Schätzen der Anzahl der benötigten Hauptkomponenten ist Gebrochene Zuckerrohrregel(Englisch) Gebrochenes Stockmodell) . Der auf die Einheitssumme (, ) normierte Satz von Eigenwerten wird mit der Verteilung der Längen von Fragmenten eines Stocks der Einheitslänge verglichen, der am zufällig ausgewählten Punkt gebrochen ist (Bruchpunkte werden unabhängig voneinander ausgewählt und sind gleichmäßig über die Länge verteilt des Stocks). Seien () die Längen der erhaltenen Rohrstücke, nummeriert in absteigender Reihenfolge der Länge: . Es ist nicht schwierig, den mathematischen Erwartungswert zu finden:
Nach der Broken-Cane-Regel wird der te Eigenvektor (in absteigender Reihenfolge der Eigenwerte) in der Liste der Hauptkomponenten gespeichert, wenn
Auf Abb. ein Beispiel für den 5-dimensionalen Fall ist gegeben:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.Zum Beispiel ausgewählt
=0.5; =0.3; =0.1; =0.06; =0.04.Gemäß der Regel eines gebrochenen Stocks sollten in diesem Beispiel 2 Hauptkomponenten übrig bleiben:
Laut Anwendern tendiert die Broken Cane Rule dazu, die Anzahl der wesentlichen Hauptkomponenten zu unterschätzen.
Normalisierung
Normalisierung nach Reduktion auf Hauptkomponenten
Nach Projektion auf die ersten Hauptkomponenten, wobei es bequem ist, auf Einheits-(Stichproben-)Varianz entlang der Achsen zu normalisieren. Die Streuung entlang der ten Hauptkomponente ist gleich ), also muss zur Normalisierung die entsprechende Koordinate durch geteilt werden. Diese Transformation ist nicht orthogonal und bewahrt das Skalarprodukt nicht. Nach der Normalisierung wird die Kovarianzmatrix der Datenprojektion zu Eins, die Projektionen in zwei beliebige orthogonale Richtungen werden zu unabhängigen Werten und jede orthonormale Basis wird zur Basis der Hauptkomponenten (denken Sie daran, dass die Normalisierung das Orthogonalitätsverhältnis der Vektoren ändert). Die Abbildung vom anfänglichen Datenraum auf die ersten Hauptkomponenten zusammen mit der Normierung ist durch die Matrix gegeben
.Diese Transformation wird am häufigsten als Karhunen-Loeve-Transformation bezeichnet. Hier sind Spaltenvektoren und hochgestellt bedeutet transponieren.
Normalisierung vor der Berechnung der Hauptkomponenten
Warnung: man sollte die nach der Transformation auf die Hauptkomponenten durchgeführte Normierung nicht mit der Normierung und "dimensionslos" verwechseln Datenvorverarbeitung durchgeführt, bevor die Hauptkomponenten berechnet werden. Eine Vornormalisierung ist für eine vernünftige Auswahl einer Metrik erforderlich, bei der die beste Annäherung der Daten berechnet wird, oder die Richtungen der größten Streuung (die äquivalent ist) gesucht werden. Wenn es sich bei den Daten beispielsweise um dreidimensionale Vektoren von „Meter, Liter und Kilogramm“ handelt, dann wird bei Verwendung der standardmäßigen euklidischen Distanz eine Differenz von 1 Meter in der ersten Koordinate den gleichen Beitrag leisten wie eine Differenz von 1 Liter in der zweiten , oder 1 kg im dritten . Normalerweise spiegeln die Einheitensysteme, in denen die Quelldaten dargestellt werden, unsere Vorstellungen von den natürlichen Skalen entlang der Achsen nicht genau wider, und es wird „dimensionslos“ ausgeführt: Jede Koordinate wird in eine bestimmte Skala unterteilt, die durch die Daten, die Zwecke, bestimmt wird ihrer Verarbeitung und die Prozesse der Messung und Erhebung von Daten.
Für eine solche Normierung gibt es drei grundsätzlich unterschiedliche Standardansätze: Einheit Varianz entlang der Achsen (die Skalen entlang der Achsen sind gleich den mittleren quadratischen Abweichungen - nach dieser Transformation stimmt die Kovarianzmatrix mit der Matrix der Korrelationskoeffizienten überein), an gleiche Messgenauigkeit(die Skala entlang der Achse ist proportional zur Messgenauigkeit eines bestimmten Werts) und weiter gleiche Ansprüche im Problem (der Maßstab entlang der Achse wird durch die erforderliche Genauigkeit der Vorhersage eines bestimmten Werts oder seiner zulässigen Verzerrung bestimmt - das Toleranzniveau). Die Wahl der Vorverarbeitung wird von der sinnvollen Problemstellung sowie den Bedingungen der Datenerhebung beeinflusst (wenn beispielsweise die Datenerhebung grundsätzlich unvollständig ist und die Daten dennoch empfangen werden, ist es nicht sinnvoll, die Normalisierung strikt zu wählen durch Einheitsvarianz, auch wenn dies der Bedeutung des Problems entspricht, da dies eine Renormierung aller Daten nach Erhalt eines neuen Teils beinhaltet; es ist sinnvoller, eine Skala zu wählen, die die Standardabweichung grob schätzt, und sie dann nicht zu ändern) .
Die Vornormierung auf Einheitsvarianz entlang der Achsen wird durch Rotation des Koordinatensystems zerstört, wenn die Achsen keine Hauptkomponenten sind, und die Normalisierung während der Datenvorverarbeitung ersetzt nicht die Normalisierung nach der Reduktion auf Hauptkomponenten.
Mechanische Analogie und Hauptkomponentenanalyse für gewichtete Daten
Wenn wir jedem Datenvektor eine Einheitsmasse zuweisen, dann fällt die empirische Kovarianzmatrix mit dem Trägheitstensor dieses Systems von Punktmassen (geteilt durch die Gesamtmasse) zusammen, und das Problem der Hauptkomponenten fällt mit dem Problem zusammen, die zu bringen Trägheitstensor zu den Hauptachsen. Sie können zusätzliche Freiheiten bei der Wahl der Massenwerte nutzen, um die Wichtigkeit von Datenpunkten oder die Zuverlässigkeit ihrer Werte zu berücksichtigen (höhere Massen werden wichtigen Daten oder Daten aus zuverlässigeren Quellen zugewiesen). Wenn ein dem Datenvektor wird eine Masse gegeben, dann erhalten wir anstelle der empirischen Kovarianzmatrix
Alle weiteren Operationen zum Reduzieren auf Hauptkomponenten werden auf die gleiche Weise wie in der Hauptversion des Verfahrens durchgeführt: Wir suchen nach einer orthonormalen Eigenbasis, ordnen sie in absteigender Reihenfolge der Eigenwerte und schätzen den gewichteten durchschnittlichen Fehler der Datennäherung durch die erste Komponenten (durch Eigenwertsummen), Normierung usw. .
Mehr allgemeiner Weg Wiegen gibt Maximieren der gewichteten Summe paarweiser Abstände zwischen Projektionen. Für alle zwei Datenpunkte wird ein Gewicht eingegeben; und . Anstelle der empirischen Kovarianzmatrix verwenden wir
Für ist die symmetrische Matrix positiv definit, weil die quadratische Form positiv ist:
Als nächstes suchen wir nach einer orthonormalen Eigenbasis , ordnen sie in absteigender Reihenfolge der Eigenwerte an, schätzen den gewichteten durchschnittlichen Fehler der Datennäherung durch die ersten Komponenten usw. - genau das gleiche wie im Hauptalgorithmus.
Diese Methode wird angewendet wenn es Unterricht gibt: Für verschiedene Klassen wird das Gewicht größer gewählt als für Punkte derselben Klasse. Dadurch werden in der Hochrechnung auf die gewichteten Hauptkomponenten die unterschiedlichen Klassen um einen größeren Abstand „auseinandergerückt“.
Andere Anwendung - Verringerung des Einflusses großer Abweichungen(Ausleger, engl. Ausreißer ), was das Bild aufgrund der Verwendung des Effektivabstands verzerren kann: Wenn Sie wählen, wird der Einfluss großer Abweichungen reduziert. Damit ist die beschriebene Modifikation der Hauptkomponentenmethode robuster als die klassische.
Spezielle Terminologie
In der Statistik werden bei der Anwendung der Hauptkomponentenmethode mehrere Fachbegriffe verwendet.
Datenmatrix; Jede Zeile ist ein Vektor vorverarbeitet Daten ( zentriert und rechts normalisiert), Anzahl Zeilen – (Anzahl Datenvektoren), Anzahl Spalten – (Dimension des Datenraums);
Matrix laden(Laden) ; jede Spalte ist der Hauptkomponentenvektor, die Anzahl der Zeilen ist (Datenraumdimension), die Anzahl der Spalten ist (die Anzahl der für die Projektion ausgewählten Hauptkomponentenvektoren);
Abrechnungsmatrix(Ergebnisse) ; jede Reihe ist die Projektion des Datenvektors auf die Hauptkomponenten; Anzahl der Zeilen – (Anzahl der Datenvektoren), Anzahl der Spalten – (Anzahl der für die Projektion ausgewählten Hauptkomponentenvektoren);
Z-Score-Matrix(Z-Scores) ; jede Reihe ist die Projektion des Datenvektors auf die Hauptkomponenten, normiert auf die Einheitsstichprobenvarianz; Anzahl der Zeilen – (Anzahl der Datenvektoren), Anzahl der Spalten – (Anzahl der für die Projektion ausgewählten Hauptkomponentenvektoren);
Fehlermatrix(oder Reste) (Fehler oder Residuen) .
Grundformel:
Grenzen der Anwendbarkeit und Grenzen der Wirksamkeit der Methode
Die Hauptkomponentenmethode ist immer anwendbar. Die weit verbreitete Behauptung, es sei nur auf normalverteilte Daten (oder auf Verteilungen nahe der Normalverteilung) anwendbar, ist falsch: In der ursprünglichen Formulierung von K. Pearson ist das Problem der Annäherungen eine endliche Menge von Daten und es gibt nicht einmal eine Hypothese über ihre statistische Erzeugung, geschweige denn über die Verteilung.
Allerdings reduziert das Verfahren die Dimensionalität unter gegebenen Genauigkeitseinschränkungen nicht immer effektiv. Gerade Linien und Ebenen liefern nicht immer eine gute Annäherung. Beispielsweise können die Daten einer gewissen Kurve mit guter Genauigkeit folgen, und diese Kurve kann im Datenraum schwierig zu lokalisieren sein. In diesem Fall erfordert das Hauptkomponentenverfahren für eine akzeptable Genauigkeit mehrere Komponenten (statt einer) oder ergibt überhaupt keine Dimensionsreduktion mit akzeptabler Genauigkeit. Um mit solchen "Kurven"-Hauptkomponenten fertig zu werden, wurden das Verfahren der Hauptverteiler und verschiedene Versionen des nichtlinearen Hauptkomponentenverfahrens erfunden. Mehr Probleme können komplexe Topologiedaten liefern. Es wurden auch verschiedene Methoden erfunden, um sie anzunähern, wie zum Beispiel selbstorganisierende Kohonen-Karten, neurales Gas oder topologische Grammatiken. Wenn die Daten statistisch mit einer stark von der Normalverteilung abweichenden Verteilung generiert werden, ist es sinnvoll, von Hauptkomponenten zu zu gehen unabhängige Komponenten, die im ursprünglichen Skalarprodukt nicht mehr orthogonal sind. Schließlich erhalten wir für eine isotrope Verteilung (sogar eine normale) anstelle eines Streuellipsoids eine Kugel, und es ist unmöglich, die Dimension durch Näherungsmethoden zu reduzieren.
Anwendungsbeispiele
Datenvisualisierung
Datenvisualisierung ist eine Präsentation in visueller Form von experimentellen Daten oder den Ergebnissen einer theoretischen Studie.
Die erste Wahl bei der Visualisierung eines Datensatzes ist die orthogonale Projektion auf die Ebene der ersten beiden Hauptkomponenten (oder den 3D-Raum der ersten drei Hauptkomponenten). Die Designebene ist im Wesentlichen ein flacher zweidimensionaler „Bildschirm“, der so positioniert ist, dass er ein „Bild“ der Daten mit der geringsten Verzerrung liefert. Eine solche Projektion ist (unter allen orthogonalen Projektionen auf verschiedenen zweidimensionalen Bildschirmen) in dreierlei Hinsicht optimal:
- Die minimale Summe der quadrierten Abstände von Datenpunkten zu Projektionen auf die Ebene der ersten Hauptkomponenten, dh der Bildschirm befindet sich so nah wie möglich an der Punktwolke.
- Die minimale Summe der Verzerrungen der quadrierten Abstände zwischen allen Punktpaaren aus der Datenwolke nach der Projektion der Punkte auf die Ebene.
- Minimale Summe der quadratischen Abstandsverzerrungen zwischen allen Datenpunkten und ihrem "Schwerpunkt".
Die Datenvisualisierung ist eine der am weitesten verbreiteten Anwendungen der Hauptkomponentenanalyse und ihrer nichtlinearen Verallgemeinerungen.
Bild- und Videokomprimierung
Um die räumliche Redundanz von Pixeln beim Codieren von Bildern und Videos zu reduzieren, werden lineare Transformationen von Pixelblöcken verwendet. Eine anschließende Quantisierung der erhaltenen Koeffizienten und eine verlustfreie Codierung ermöglichen es, signifikante Kompressionskoeffizienten zu erhalten. Die Verwendung der PCA-Transformation als lineare Transformation ist für einige Datentypen im Hinblick auf die Größe der resultierenden Daten mit der gleichen Verzerrung optimal. Derzeit wird diese Methode nicht aktiv genutzt, hauptsächlich aufgrund des hohen Rechenaufwands. Außerdem kann eine Datenkomprimierung erreicht werden, indem die letzten Transformationskoeffizienten verworfen werden.
Rauschunterdrückung in Bildern
Chemometrie
Die Hauptkomponentenmethode ist eine der wichtigsten Methoden in der Chemometrie. Chemometrie ). Ermöglicht es Ihnen, die Matrix der Anfangsdaten X in zwei Teile zu unterteilen: "aussagekräftig" und "Rauschen". Gemäß der gängigsten Definition ist „Chemometrie die chemische Disziplin, die mathematische, statistische und andere Methoden auf der Grundlage formaler Logik anwendet, um optimale Messmethoden und experimentelle Designs zu konstruieren oder auszuwählen und die wichtigsten Informationen bei der Analyse experimenteller Daten zu extrahieren. "
Psychodiagnostik
- Datenanalyse (Beschreibung der Ergebnisse von Umfragen oder anderen Studien, dargestellt in Form von Arrays numerischer Daten);
- Beschreibung sozialer Phänomene (Konstruktion von Phänomenmodellen, einschließlich mathematischer Modelle).
In der Politikwissenschaft war die Hauptkomponentenmethode das Hauptwerkzeug des Projekts „Politischer Atlas der Moderne“ zur linearen und nichtlinearen Analyse der Bewertungen von 192 Ländern der Welt nach fünf eigens entwickelten integralen Indizes (Lebensstandard, International Einfluss, Drohungen, Staatlichkeit und Demokratie). Zur Kartographie der Ergebnisse dieser Analyse wurde ein spezielles GIS (Geoinformationssystem) entwickelt, das den geographischen Raum mit dem Merkmalsraum verbindet. Politische Atlas-Datenkarten wurden auch unter Verwendung von 2D-Hauptverteilern im 5D-Landraum als Hintergrund erstellt. Der Unterschied zwischen einer Datenkarte und einer geografischen Karte besteht darin, dass auf einer geografischen Karte Objekte in der Nähe mit ähnlichen geografischen Koordinaten vorhanden sind, während auf einer Datenkarte Objekte (Länder) mit ähnlichen Merkmalen (Indizes) in der Nähe vorhanden sind.
Die Quelle für die Analyse ist die Datenmatrix
Maße  , deren i-te Zeile die i-te Beobachtung (Objekt) für alle k Indikatoren charakterisiert
, deren i-te Zeile die i-te Beobachtung (Objekt) für alle k Indikatoren charakterisiert  . Die Ausgangsdaten werden normalisiert, für die die Durchschnittswerte der Indikatoren berechnet werden
. Die Ausgangsdaten werden normalisiert, für die die Durchschnittswerte der Indikatoren berechnet werden  , sowie die Werte der Standardabweichungen
, sowie die Werte der Standardabweichungen  . Dann die Matrix der normalisierten Werte
. Dann die Matrix der normalisierten Werte

mit Elementen 
Die Matrix der gepaarten Korrelationskoeffizienten wird berechnet:

Einzelne Elemente befinden sich auf der Hauptdiagonalen der Matrix  .
.
Das Komponentenanalysemodell wird erstellt, indem die ursprünglichen normalisierten Daten als lineare Kombination der Hauptkomponenten dargestellt werden:

wo  - "Gewicht", d.h. Faktorladung
- "Gewicht", d.h. Faktorladung  -ten Hauptkomponente auf
-ten Hauptkomponente auf  -te Variable;
-te Variable;
 -Bedeutung
-Bedeutung  te Hauptkomponente für
te Hauptkomponente für  te Beobachtung (Objekt), wo
te Beobachtung (Objekt), wo  .
.
In Matrixform hat das Modell die Form

hier  - Matrix der Hauptkomponenten der Dimension
- Matrix der Hauptkomponenten der Dimension  ,
,
 - Matrix von Faktorladungen derselben Dimension.
- Matrix von Faktorladungen derselben Dimension.
Matrix  beschreibt
beschreibt  Beobachtungen im Weltraum
Beobachtungen im Weltraum  Hauptbestandteile. In diesem Fall die Elemente der Matrix
Hauptbestandteile. In diesem Fall die Elemente der Matrix  normalisiert sind und die Hauptkomponenten nicht miteinander korreliert sind. Es folgt dem
normalisiert sind und die Hauptkomponenten nicht miteinander korreliert sind. Es folgt dem 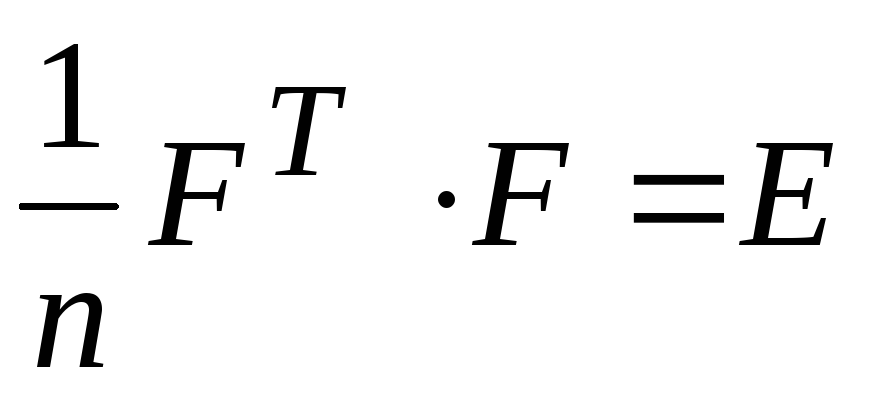 , wo
, wo  ist die Identitätsmatrix der Dimension
ist die Identitätsmatrix der Dimension  .
.
Element  Matrizen
Matrizen  charakterisiert die Enge der linearen Beziehung zwischen der ursprünglichen Variablen
charakterisiert die Enge der linearen Beziehung zwischen der ursprünglichen Variablen  und Hauptbestandteil
und Hauptbestandteil  nimmt daher die Werte an
nimmt daher die Werte an  .
.
Korrelationsmatrix  kann in Form der Faktorladungsmatrix ausgedrückt werden
kann in Form der Faktorladungsmatrix ausgedrückt werden  .
.
Entlang der Hauptdiagonalen der Korrelationsmatrix befinden sich Einheiten, die in Analogie zur Kovarianzmatrix die Varianzen der verwendeten Werte darstellen  -Features, aber im Gegensatz zu letzterem sind diese Varianzen aufgrund der Normalisierung gleich 1. Die Gesamtvarianz des gesamten Systems
-Features, aber im Gegensatz zu letzterem sind diese Varianzen aufgrund der Normalisierung gleich 1. Die Gesamtvarianz des gesamten Systems  -Features im Beispielsatz von Volumen
-Features im Beispielsatz von Volumen  ist gleich der Summe dieser Einheiten, d.h. gleich der Spur der Korrelationsmatrix
ist gleich der Summe dieser Einheiten, d.h. gleich der Spur der Korrelationsmatrix  .
.
Korrelationsmatrizen lassen sich in eine diagonale umwandeln, also eine Matrix, bei der alle Werte, außer den diagonalen, gleich Null sind:
 ,
,
wo  ist eine Diagonalmatrix mit Eigenwerten auf ihrer Hauptdiagonalen
ist eine Diagonalmatrix mit Eigenwerten auf ihrer Hauptdiagonalen  Korrelationsmatrix,
Korrelationsmatrix,  ist eine Matrix, deren Spalten die Eigenvektoren der Korrelationsmatrix sind
ist eine Matrix, deren Spalten die Eigenvektoren der Korrelationsmatrix sind  . Da die Matrix R positiv definit ist, d.h. seine Hauptminoren positiv sind, dann alle Eigenwerte
. Da die Matrix R positiv definit ist, d.h. seine Hauptminoren positiv sind, dann alle Eigenwerte  für alle
für alle  .
.
Eigenwerte  werden als Wurzeln der charakteristischen Gleichung gefunden
werden als Wurzeln der charakteristischen Gleichung gefunden

Eigenvektor  entspricht dem Eigenwert
entspricht dem Eigenwert  Korrelationsmatrix
Korrelationsmatrix  , ist als eine von Null verschiedene Lösung der Gleichung definiert
, ist als eine von Null verschiedene Lösung der Gleichung definiert

Normalisierter Eigenvektor  gleich
gleich

Das Verschwinden von Termen außerhalb der Diagonale bedeutet, dass die Merkmale voneinander unabhängig werden ( 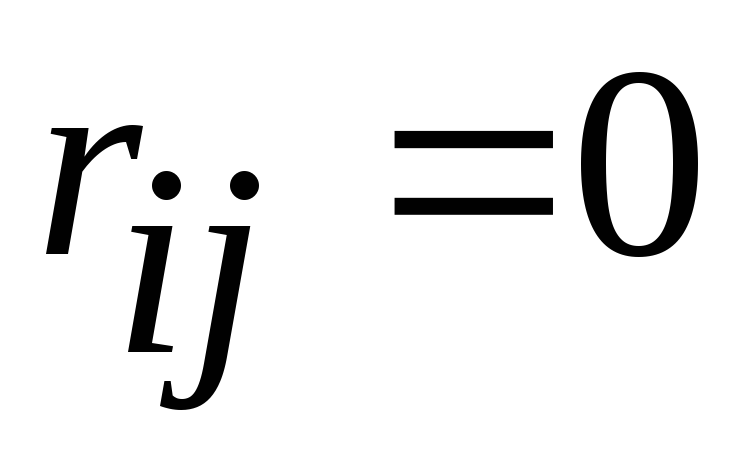 bei
bei  ).
).
Gesamtvarianz des gesamten Systems  Variablen in der Probe bleibt gleich. Seine Werte werden jedoch neu verteilt. Das Verfahren zum Finden der Werte dieser Varianzen besteht darin, die Eigenwerte zu finden
Variablen in der Probe bleibt gleich. Seine Werte werden jedoch neu verteilt. Das Verfahren zum Finden der Werte dieser Varianzen besteht darin, die Eigenwerte zu finden  Korrelationsmatrix für jeden von
Korrelationsmatrix für jeden von 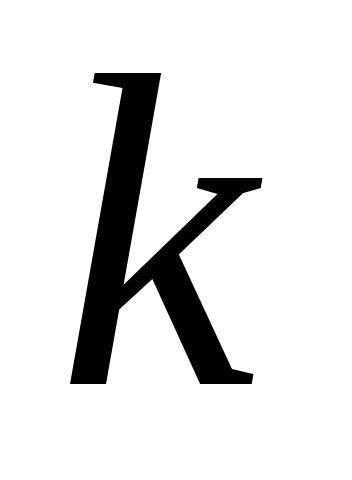 -Zeichen. Die Summe dieser Eigenwerte
-Zeichen. Die Summe dieser Eigenwerte  ist gleich der Spur der Korrelationsmatrix, d.h.
ist gleich der Spur der Korrelationsmatrix, d.h.  , also die Anzahl der Variablen. Diese Eigenwerte sind die Werte der Merkmalsvarianz
, also die Anzahl der Variablen. Diese Eigenwerte sind die Werte der Merkmalsvarianz  unter Bedingungen, in denen die Zeichen voneinander unabhängig wären.
unter Bedingungen, in denen die Zeichen voneinander unabhängig wären.
Bei der Hauptkomponentenmethode wird zunächst aus den Ausgangsdaten die Korrelationsmatrix berechnet. Dann wird seine orthogonale Transformation durchgeführt und dadurch die Faktorladungen gefunden  für alle
für alle  Variablen und
Variablen und  Faktoren (Matrix der Faktorladungen), Eigenwerte
Faktoren (Matrix der Faktorladungen), Eigenwerte  und bestimmen Sie die Gewichte der Faktoren.
und bestimmen Sie die Gewichte der Faktoren.
Die Faktorladungsmatrix A kann definiert werden als 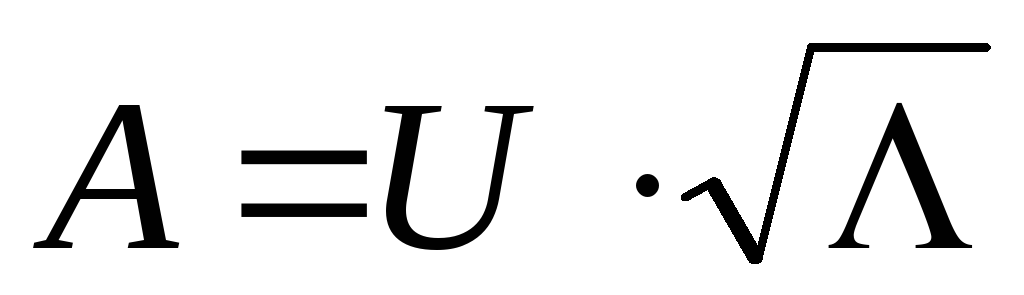 , a
, a  -te Spalte der Matrix A - als
-te Spalte der Matrix A - als  .
.
Gewicht der Faktoren  oder
oder  spiegelt den Anteil dieses Faktors an der Gesamtvarianz wider.
spiegelt den Anteil dieses Faktors an der Gesamtvarianz wider.
Faktorladungen variieren von -1 bis +1 und sind analog zu Korrelationskoeffizienten. In der Matrix der Faktorladungen muss mit dem Student-t-Test zwischen signifikanten und insignifikanten Ladungen unterschieden werden  .
.
Summe der quadrierten Lasten  -ten Faktor insgesamt
-ten Faktor insgesamt  -features ist gleich dem Eigenwert dieses Faktors
-features ist gleich dem Eigenwert dieses Faktors  . Dann
. Dann  -Beitrag der i-ten Variablen in % zur Bildung des j-ten Faktors.
-Beitrag der i-ten Variablen in % zur Bildung des j-ten Faktors.
Die Summe der Quadrate aller Faktorladungen in einer Reihe ist gleich eins, die volle Varianz einer Variablen und aller Faktoren in allen Variablen ist gleich der Gesamtvarianz (d. h. die Spur oder Ordnung der Korrelationsmatrix oder die Summe seiner Eigenwerte)  .
.
Im Allgemeinen wird die Faktorenstruktur des i-ten Merkmals im Formular dargestellt  , die nur signifikante Lasten enthält. Mithilfe der Faktorladungsmatrix können Sie die Werte aller Faktoren für jede Beobachtung der Originalstichprobe nach der Formel berechnen:
, die nur signifikante Lasten enthält. Mithilfe der Faktorladungsmatrix können Sie die Werte aller Faktoren für jede Beobachtung der Originalstichprobe nach der Formel berechnen:
 ,
,
wo  ist der Wert des j-ten Faktors in der t-ten Beobachtung,
ist der Wert des j-ten Faktors in der t-ten Beobachtung,  - standardisierter Wert des i-ten Merkmals der t-ten Beobachtung der Originalprobe;
- standardisierter Wert des i-ten Merkmals der t-ten Beobachtung der Originalprobe;  – Faktorbelastung,
– Faktorbelastung,  ist der dem Faktor j entsprechende Eigenwert. Diese berechneten Werte
ist der dem Faktor j entsprechende Eigenwert. Diese berechneten Werte  werden häufig zur grafischen Darstellung der Ergebnisse der Faktorenanalyse verwendet.
werden häufig zur grafischen Darstellung der Ergebnisse der Faktorenanalyse verwendet.
Gemäß der Matrix der Faktorladungen kann die Korrelationsmatrix wiederhergestellt werden:  .
.
Der Anteil der Varianz einer Variablen, der durch die Hauptkomponenten erklärt wird, wird als Kommunalität bezeichnet.
 ,
,
wo  ist die Nummer der Variablen, und
ist die Nummer der Variablen, und  - die Nummer der Hauptkomponente. Die nur aus den Hauptkomponenten rekonstruierten Korrelationskoeffizienten sind im absoluten Wert kleiner als die anfänglichen, und auf der Diagonale steht nicht 1, sondern die Werte der Gemeinsamkeit.
- die Nummer der Hauptkomponente. Die nur aus den Hauptkomponenten rekonstruierten Korrelationskoeffizienten sind im absoluten Wert kleiner als die anfänglichen, und auf der Diagonale steht nicht 1, sondern die Werte der Gemeinsamkeit.
Spezifischer Beitrag  te Hauptkomponente wird durch die Formel bestimmt
te Hauptkomponente wird durch die Formel bestimmt
 .
.
Der Gesamtbeitrag von  Hauptkomponenten wird aus dem Ausdruck bestimmt
Hauptkomponenten wird aus dem Ausdruck bestimmt
 .
.
Wird normalerweise für Analysen verwendet  die ersten Hauptkomponenten, deren Beitrag zur Gesamtvarianz 60–70 % übersteigt.
die ersten Hauptkomponenten, deren Beitrag zur Gesamtvarianz 60–70 % übersteigt.
Die Faktorladungsmatrix A wird verwendet, um die Hauptkomponenten zu interpretieren, und Werte über 0,5 werden normalerweise berücksichtigt.
Die Werte der Hauptkomponenten sind durch die Matrix gegeben






