Pe ce se bazează metoda componentelor principale? Aplicarea metodei componentelor principale pentru prelucrarea datelor statistice multivariate. Aplicarea analizei componentelor principale
Metoda componentei principale(PCA - Analiza componentelor principale) este una dintre principalele modalități de reducere a dimensiunii datelor cu cea mai mică pierdere de informații. Inventat în 1901 de Karl Pearson, este utilizat pe scară largă în multe domenii. De exemplu, pentru compresia datelor, „viziune pe computer”, recunoaștere vizibilă a modelelor etc. Calculul componentelor principale se reduce la calculul vectorilor proprii și al valorilor proprii ale matricei de covarianță a datelor originale. Metoda componentei principale este adesea denumită Transformarea Karhunen-Löwe(transformarea Karhunen-Loeve) sau Hotelling transform(Transformarea hotelieră). La această problemă au lucrat și matematicienii Kosambi (1943), Pugaciov (1953) și Obukhova (1954).
Problema analizei componentelor principale are ca scop aproximarea (aproximativa) a datelor prin varietăți liniare de dimensiune inferioară; găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care răspândirea datelor (adică abaterea standard de la valoarea medie) este maximă; găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care distanța pătratică medie dintre puncte este maximă. În acest caz, se operează cu seturi finite de date. Sunt echivalente și nu folosesc nicio ipoteză despre generarea datelor statistice.
În plus, sarcina analizei componentelor principale poate fi scopul de a construi pentru o anumită variabilă aleatoare multidimensională o astfel de transformare ortogonală a coordonatelor care, ca urmare, corelațiile dintre coordonatele individuale vor dispărea. Această versiune funcționează variabile aleatoare.
Fig.3
Figura de mai sus prezintă punctele P i pe plan, p i este distanța de la P i la dreapta AB. Se caută o dreaptă AB care să minimizeze suma
Metoda componentelor principale a început cu problema celei mai bune aproximări (aproximații) a unui set finit de puncte prin linii drepte și plane. De exemplu, dat un set finit de vectori. Pentru fiecare k = 0,1,...,n ? 1 dintre toate varietățile liniare k-dimensionale în găsiți astfel încât suma abaterilor pătrate ale lui x i de la L k este minimă:
Unde? Distanța euclidiană de la un punct la o varietate liniară.
Orice varietate liniară k-dimensională în poate fi definită ca un set de combinații liniare, unde parametrii din i trec prin linia reală, nu? set ortonormal de vectori
unde este norma euclidiană? Produs punctual euclidian sau sub formă de coordonate:
Rezolvarea problemei de aproximare pentru k = 0,1,...,n ? 1 este dat de un set de varietati liniare imbricate
Aceste varietăți liniare sunt definite de o mulțime ortonormală de vectori (vectori componente principale) și un vector a 0 . Vectorul a 0 este căutat ca soluție la problema de minimizare pentru L 0:


Rezultatul este un exemplu de medie:
Matematicianul francez Maurice Frechet Frechet Maurice René (09/02/1878 - 06/04/1973) este un matematician francez remarcabil. A lucrat în domeniul topologiei și analizei funcționale, teoria probabilității. Autor concepte moderne despre spațiu metric, compactitate și completitudine. Auth. în 1948 a observat că definiția variațională a mediei ca punct care minimizează suma distanțelor pătrate la punctele de date este foarte convenabilă pentru construirea de statistici într-un spațiu metric arbitrar și a construit o generalizare a statisticilor clasice pentru spațiile generale, numită metoda generalizată. de cele mai mici pătrate.
Vectorii componente principale pot fi găsiți ca soluții la probleme similare de optimizare:
1) centralizați datele (scădeți media):
2) găsiți prima componentă principală ca soluție a problemei;

3) Scădeți din date proiecția pe prima componentă principală:
4) găsiți a doua componentă principală ca soluție la problemă

Dacă soluția nu este unică, atunci alegeți una dintre ele.
2k-1) Scădeți proiecția pe (k ? 1)-a componentă principală (rețineți că proiecțiile asupra componentelor principale anterioare (k ? 2) au fost deja scăzute):
2k) găsim k-a principală componenta ca solutie la problema:

Dacă soluția nu este unică, atunci alegeți una dintre ele.

Orez. 4
Prima componentă principală maximizează varianța eșantionului a proiecției datelor.
De exemplu, să presupunem că ni se oferă un set centrat de vectori de date în care media aritmetică a lui x i este zero. Sarcină? găsiți o astfel de transformare ortogonală într-un nou sistem de coordonate pentru care următoarele condiții ar fi adevărate:
1. Varianta eșantion de date de-a lungul primei coordonate ( componenta principală) este maximă;
2. Varianța eșantionului de date de-a lungul celei de-a doua coordonate (a doua componentă principală) este maximă în condițiile ortogonalității față de prima coordonată;
3. Dispersia eșantionului de date de-a lungul valorilor coordonatei k este maximă în condițiile ortogonalității față de primul k ? 1 coordonate;
Varianta eșantionului de date de-a lungul direcției date de vectorul normalizat a k este
(deoarece datele sunt centrate, varianța eșantionului aici este aceeași cu abaterea medie pătrată de la zero).
Rezolvarea celei mai bune probleme de potrivire produce același set de componente principale ca și găsirea proiecțiilor ortogonale cu cea mai mare împrăștiere, dintr-un motiv foarte simplu:
iar primul termen nu depinde de un k .
Matricea de conversie a datelor în componente principale este construită din vectorii "A" ai componentelor principale:
Aici ai sunt vectori coloană ortonormali ai componentelor principale aranjate în ordinea descrescătoare a valorilor proprii, superscriptul T înseamnă transpunere. Matricea A este ortogonală: AA T = 1.
După transformare, cea mai mare parte a variației datelor va fi concentrată în primele coordonate, ceea ce face posibilă eliminarea celor rămase și luarea în considerare a unui spațiu cu dimensiuni reduse.
Cea mai veche metodă de selecție a componentelor principale este regula lui Kaiser, Kaiser Johann Henrich Gustav (Kaiser Johann Henrich Gustav, 16.03.1853, Brezno, Prusia - 14.10.1940, Germania) - un remarcabil matematician, fizician, cercetător în domeniul analizei spectrale. Auth. conform căreia acele componente principale sunt semnificative pentru care
adică l i depășește valoarea medie a lui l (varianța medie a eșantionului a coordonatelor vectorului de date). Regula lui Kaiser funcționează bine în cazurile simple în care există mai multe componente principale cu l i care sunt mult mai mari decât media, iar restul valorilor proprii sunt mai mici decât aceasta. În cazuri mai complexe, poate da prea multe componente principale semnificative. Dacă datele sunt normalizate la varianța eșantionului unitar de-a lungul axelor, atunci regula Kaiser ia o formă deosebit de simplă: numai acele componente principale sunt semnificative pentru care l i > 1.
Una dintre cele mai populare abordări euristice pentru estimarea numărului de componente principale necesare este regula bastonului rupt, atunci când mulțimea valorilor proprii (, i = 1,...n) normalizate la suma unitară este comparată cu distribuția lungimii fragmentelor unui baston de lungime unitară ruptă la n ? Primul punct selectat aleatoriu (punctele de rupere sunt alese independent și sunt distribuite egal pe lungimea bastonului). Dacă L i (i = 1,...n) sunt lungimile pieselor de trestie obținute, numerotate în ordinea descrescătoare a lungimii: , atunci așteptarea lui L i:

Să luăm în considerare un exemplu care constă în estimarea numărului de componente principale după regula bastonului rupt în dimensiunea 5.

Orez. 5.
După regula bastonului rupt k-al-lea propriu vectorul (în ordinea descrescătoare a valorilor proprii l i) este stocat în lista componentelor principale dacă
Figura de mai sus prezintă un exemplu pentru cazul cu 5 dimensiuni:
l 1 =(1+1/2+1/3+1/4+1/5)/5; l 2 =(1/2+1/3+1/4+1/5)/5; l 3 \u003d (1/3 + 1/4 + 1/5) / 5;
l 4 \u003d (1/4 + 1/5) / 5; l 5 \u003d (1/5) / 5.
De exemplu, selectat
0.5; =0.3; =0.1; =0.06; =0.04.
Conform regulii unui baston rupt, în acest exemplu ar trebui lăsate 2 componente principale:
Trebuie reținut doar că regula bastonului rupt tinde să subestimeze numărul de componente principale semnificative.
După proiectarea pe primele k componente principale c, este convenabil să se normalizeze la varianța unității (eșantionului) de-a lungul axelor. Dispersia de-a lungul celei de-a i-a componente principale este egală), deci pentru normalizare este necesară împărțirea coordonatei corespunzătoare la. Această transformare nu este ortogonală și nu păstrează produsul punctual. După normalizare, matricea de covarianță a proiecției datelor devine unitate, proiecțiile către oricare două direcții ortogonale devin valori independente și orice bază ortonormală devine baza componentelor principale (reamintim că normalizarea modifică raportul de ortogonalitate al vectorilor). Maparea din spațiul de date inițial la primele k componente principale împreună cu normalizarea este dată de matrice

Această transformare este cea mai adesea numită transformarea Karhunen-Loeve, adică metoda componentelor principale în sine. Aici a i sunt vectori coloană și superscriptul T înseamnă transpunere.
În statistică, atunci când se utilizează metoda componentelor principale, se folosesc mai mulți termeni speciali.
Data Matrix, unde fiecare rând este un vector de date preprocesate (centrate și normalizate corespunzător), numărul de rânduri este m (numărul de vectori de date), numărul de coloane este n (dimensiunea spațiului de date);
Încărcare matrice(Încărcări) , unde fiecare coloană este un vector de componentă principală, numărul de rânduri este n (dimensiunea spațiului de date), numărul de coloane este k (numărul de vectori de componentă principală selectați pentru proiecție);
Matricea de facturare(Scoruri)
unde fiecare rând este proiecția vectorului de date pe k componente principale; numărul de rânduri - m (numărul de vectori de date), numărul de coloane - k (numărul de vectori de componente principale selectați pentru proiecție);
Matricea scorului Z(scoruri Z)

unde fiecare rând este proiecția vectorului de date pe k componente principale, normalizate la varianța eșantionului unitar; numărul de rânduri - m (numărul de vectori de date), numărul de coloane - k (numărul de vectori de componente principale selectați pentru proiecție);
Matricea erorilor (resturi) (Erori sau reziduuri)
Formula de baza:
Astfel, Metoda componentei principale este una dintre principalele metode de statistică matematică. Scopul său principal este de a face distincția între necesitatea de a studia matricele de date cu un minim de utilizare a acestora.
În efortul de a descrie cu exactitate zona de studiu, analiștii selectează adesea un număr mare de variabile independente (p). În acest caz, poate apărea o eroare gravă: mai multe variabile descriptive pot caracteriza aceeași latură a variabilei dependente și, ca urmare, pot fi foarte corelate între ele. Multicoliniaritatea variabilelor independente distorsionează serios rezultatele studiului, deci ar trebui eliminată.
Analiza componentelor principale (ca model simplificat de analiză factorială, deoarece această metodă nu utilizează factori individuali care descriu doar o variabilă x i) vă permite să combinați influența variabilelor foarte corelate într-un singur factor care caracterizează variabila dependentă dintr-o singură parte. Ca urmare a analizei efectuate folosind metoda componentelor principale, vom realiza compresia informatiilor la dimensiunea ceruta, descrierea variabilei dependente m (m Mai întâi trebuie să decideți câți factori să evidențiați în acest studiu. În cadrul metodei componentelor principale, primul factor principal descrie cel mai mare procent al varianței variabilelor independente, apoi în ordine descrescătoare. Astfel, fiecare componentă principală următoare, identificată secvenţial, explică o pondere tot mai mică a variabilităţii factorilor x i . Sarcina cercetătorului este să determine când variabilitatea devine cu adevărat mică și aleatorie. Cu alte cuvinte, câte componente principale ar trebui selectate pentru o analiză ulterioară. Există mai multe metode de selecție rațională a numărului necesar de factori. Cel mai folosit dintre ele este criteriul Kaiser. În conformitate cu acest criteriu, sunt selectați doar acei factori ale căror valori proprii sunt mai mari decât 1. Astfel, se omite un factor care nu explică varianța echivalentă cu cel puțin varianța unei variabile. Să analizăm Tabelul 19 construit în SPSS: Tabelul 19. Varianța totală explicată După cum se poate observa din Tabelul 19, în acest studiu, variabilele x i sunt foarte corelate între ele (acest lucru a fost identificat și mai devreme și poate fi observat din Tabelul 5 „Coeficienți de corelație perechi”) și, prin urmare, caracterizează variabila dependentă Y aproape pe de o parte: inițial, prima componentă principală explică 90,7% din varianța x i și doar valoarea proprie corespunzătoare primei componente principale este mai mare decât 1. Desigur, acesta este un neajuns al selecției datelor, dar acest neajuns nu a fost evidentă în timpul selecției în sine. Analiza din pachetul SPSS vă permite să alegeți singur numărul de componente principale. Să alegem numărul 6 - egal cu numărul de variabile independente. A doua coloană a tabelului 19 arată sumele pătratelor sarcinilor de rotație, tocmai din aceste rezultate vom concluziona numărul de factori. Valorile proprii corespunzătoare primelor două componente principale sunt mai mari decât 1 (55,246%, respectiv 38,396%), prin urmare, conform metodei Kaiser, selectăm cele 2 componente principale cele mai semnificative. A doua metodă de selectare a numărului necesar de factori este criteriul „scree”. Conform acestei metode, valorile proprii sunt prezentate sub forma unui grafic simplu, iar pe grafic este ales un loc unde scăderea valorilor proprii de la stânga la dreapta încetinește cât mai mult posibil: Figura 3. Criteriul Scree După cum se poate observa în figura 3, scăderea valorilor proprii încetinește deja de la a doua componentă, dar rata constantă de scădere (foarte mică) începe doar de la a treia componentă. Prin urmare, primele două componente principale vor fi selectate pentru o analiză ulterioară. Această concluzie este în concordanță cu concluzia obținută prin metoda Kaiser. Astfel, primele două componente principale obţinute secvenţial sunt în cele din urmă selectate. După evidențierea principalelor componente care vor fi utilizate în analiza ulterioară, este necesar să se determine corelația variabilelor inițiale x i cu factorii obținuți și, pe baza acesteia, să se dea denumirile componentelor. Pentru analiză, folosim matricea încărcărilor factoriale A, ale cărei elemente sunt coeficienții de corelație ai factorilor cu variabilele independente originale: Tabelul 20. Matricea de încărcare a factorilor În acest caz, interpretarea coeficienților de corelație este dificilă, prin urmare, este destul de dificil de a numi primele două componente principale. Prin urmare, vom folosi în continuare metoda de rotație ortogonală a sistemului de coordonate Varimax, al cărei scop este de a roti factorii astfel încât să alegem cea mai simplă structură a factorilor pentru interpretare: Tabelul 21. Coeficienți de interpretare Tabelul 21 arată că prima componentă principală este cel mai asociată cu variabilele x1, x2, x3; iar al doilea - cu variabilele x4, x5, x6. Astfel, se poate concluziona că volumul investițiilor în active fixe în regiune (variabila Y) depinde de doi factori: - volumul fondurilor proprii și împrumutate primite de întreprinderile din regiune pentru perioada (prima componentă, z1); -
precum și asupra intensității investițiilor întreprinderilor din regiune în active financiare și cantității de capital străin din regiune (a doua componentă, z2). Figura 4. Scatterplot Acest grafic arată rezultate dezamăgitoare. Chiar la începutul studiului, am încercat să selectăm datele astfel încât variabila rezultată Y să fie distribuită normal și practic am reușit. Legile de distribuție a variabilelor independente erau destul de departe de a fi normale, dar am încercat să le aducem cât mai aproape de legea normală (selectați datele corespunzător). Figura 4 arată că ipoteza inițială despre apropierea legii de distribuție a variabilelor independente de legea normală nu este confirmată: forma norului ar trebui să semene cu o elipsă, în centru obiectele ar trebui să fie situate mai dens decât la margini. Este de remarcat faptul că realizarea unui eșantion multivariat în care toate variabilele sunt distribuite conform legii normale este o sarcină care poate fi realizată cu mare dificultate (mai mult, nu are întotdeauna o soluție). Cu toate acestea, acest obiectiv trebuie să fie urmărit: atunci rezultatele analizei vor fi mai semnificative și mai ușor de înțeles în interpretare. Din păcate, în cazul nostru, când s-a făcut cea mai mare parte a lucrărilor de analiză a datelor colectate, este destul de dificil să se schimbe eșantionul. Dar în continuare, în lucrările ulterioare, merită să luăm o abordare mai serioasă a selecției variabilelor independente și să aducem legea distribuției lor cât mai aproape de normal. Ultima etapă a analizei componentelor principale este construirea unei ecuații de regresie pentru componentele principale (în acest caz, pentru prima și a doua componentă principală). Folosind SPSS, calculăm parametrii modelului de regresie: Tabelul 22. Parametrii ecuației de regresie a componentei principale Ecuația de regresie va lua forma: y=47414,184 + 0,916*z1+0,213*z2, (b0) (b1) (b2) Acea. b0=47 414,184
arată punctul de intersecție al regresiei directe cu axa indicatorului rezultat; b1= 0,916 – cu o creștere a valorii factorului z1 cu 1, valoarea medie așteptată a sumei investiției în active fixe va crește cu 0,916; b2= 0,213 – cu o creștere a valorii factorului z2 cu 1, valoarea medie așteptată a sumei investiției în active fixe va crește cu 0,213. În acest caz, valoarea tcr ("alfa"=0,001, "nu"=53) = 3,46 este mai mică decât tobs pentru toți coeficienții "beta". Prin urmare, toți coeficienții sunt semnificativi. Tabelul 24. Calitatea modelului de regresie a componentelor principale Tabelul 24 reflectă indicatorii care caracterizează calitatea modelului construit și anume: R - coeficient de corelație multiplă - indică ce proporție a varianței Y este explicată prin variația Z; R ^ 2 - mulţimea determinării - arată ponderea variaţiei explicate a abaterilor Y faţă de valoarea medie a acesteia. Eroarea standard a estimării caracterizează eroarea modelului construit. Să comparăm acești indicatori cu cei ai modelului de regresie al legii puterii (calitatea acestuia s-a dovedit a fi mai mare decât calitatea modelului liniar, așa că îl comparăm cu cel al legii puterii): Tabelul 25. Calitatea modelului de regresie a puterii Astfel, coeficientul de corelație multiplă R și coeficientul de determinare R^2 în modelul de putere sunt ceva mai mari decât în modelul cu componente principale. De asemenea, eroarea standard a modelului de componentă principală este MULT mai mare decât cea a modelului de putere. Prin urmare, calitatea unui model de regresie cu legea puterii este mai mare decât cea a unui model de regresie bazat pe componentele principale. Să verificăm modelul de regresie al componentelor principale, adică să analizăm semnificația acestuia. Să verificăm ipoteza despre nesemnificația modelului, să calculăm F(obs.) = 204,784 (calculat în SPSS), F(crit) (0,001; 2; 53) = 7,76. F(obs)>F(crit), prin urmare, ipoteza despre nesemnificația modelului este respinsă. Modelul este semnificativ. Deci, în urma analizei componente, s-a constatat că din variabilele independente selectate x i se pot distinge 2 componente principale - z1 și z2, iar z1 este mai influențat de variabilele x1, x2, x3 și z2 - prin x4, x5, x6. Ecuația de regresie construită pe componentele principale s-a dovedit a fi semnificativă, deși este de calitate inferioară ecuației de regresie a puterii. Conform ecuației de regresie a componentelor principale, Y este dependent pozitiv atât de Z1, cât și de Z2. Totuși, multicoliniaritatea inițială a variabilelor xi și faptul că acestea nu sunt distribuite conform legii distribuției normale pot distorsiona rezultatele modelului construit și îl pot face mai puțin semnificativ. analiza grupului Următoarea etapă a acestui studiu este analiza clusterului. Sarcina analizei cluster este de a împărți regiunile selectate (n=56) într-un număr relativ mic de grupuri (clustere) pe baza proximității lor naturale în raport cu valorile variabilelor x i . La efectuarea analizei cluster, presupunem că proximitatea geometrică a două sau mai multe puncte din spațiu înseamnă proximitatea fizică a obiectelor corespunzătoare, omogenitatea acestora (în cazul nostru, omogenitatea regiunilor în ceea ce privește indicatorii care afectează investiția în active fixe). În prima etapă a analizei clusterelor, este necesar să se determine numărul optim de clustere alocate. Pentru a face acest lucru, este necesar să se efectueze gruparea ierarhică - combinația secvențială a obiectelor în grupuri până când rămân două grupuri mari, unindu-se într-unul la distanța maximă unul de celălalt. Rezultatul analizei ierarhice (concluzie despre numărul optim de clustere) depinde de metoda de calcul a distanței dintre clustere. Deci, să testăm diverse metodeși trageți concluziile corespunzătoare. Metoda celui mai apropiat vecin Dacă calculăm distanța dintre obiecte individuale într-un singur mod - ca o simplă distanță euclidiană - distanța dintre clustere este calculată prin diferite metode. Conform metodei celui mai apropiat vecin, distanța dintre clustere corespunde distanței minime dintre două obiecte din clustere diferite. Analiza în pachetul SPSS se desfășoară după cum urmează. Mai întâi, se calculează matricea distanței dintre toate obiectele și apoi, pe baza matricei distanței, obiectele sunt combinate secvenţial în grupuri (pentru fiecare pas, matricea este compilată din nou). Pașii îmbinării secvențiale sunt prezentați în tabel: Tabelul 26 Etapele de aglomerare. Metoda celui mai apropiat vecin După cum se poate observa din Tabelul 26, în prima etapă, elementele 7 și 8 au fost combinate, deoarece distanța dintre ele a fost minimă - 0,003. În plus, distanța dintre obiectele îmbinate crește. Tabelul arată, de asemenea, numărul optim de clustere. Pentru a face acest lucru, trebuie să vă uitați la ce pas are loc un salt brusc în valoarea distanței și să scădeți numărul acestei aglomerări din numărul de obiecte studiate. În cazul nostru: (56-53)=3 este numărul optim de clustere. Figura 5. Dendrograma. Metoda celui mai apropiat vecin O concluzie similară despre numărul optim de clustere poate fi făcută privind dendrogramă (Fig. 5): trebuie selectate 3 clustere, iar primul cluster va include obiecte numerotate 1-54 (54 de obiecte în total), iar al doilea. și al treilea cluster - câte un obiect (numerotat 55 și, respectiv, 56). Acest rezultat sugerează că primele 54 de regiuni sunt relativ omogene în ceea ce privește indicatorii care afectează investițiile în active fixe, în timp ce obiectele cu numărul 55 (Republica Daghestan) și 56 (regiunea Novosibirsk) se evidențiază semnificativ din contextul general. Este de remarcat faptul că aceste entități au cele mai mari volume de investiții în active fixe dintre toate regiunile selectate. Acest fapt dovedește încă o dată dependența mare a variabilei rezultate (volumul investițiilor) de variabilele independente alese. Raționament similar este efectuat pentru alte metode de calcul a distanței dintre clustere. Metoda vecinului îndepărtat Tabelul 27 Etapele de aglomerare. Metoda vecinului îndepărtat Cu metoda vecinului îndepărtat, distanța dintre clustere este calculată ca distanta maximaîntre două obiecte din două grupuri diferite. Conform Tabelului 27, numărul optim de clustere este (56-53)=3. Figura 6. Dendrograma. Metoda vecinului îndepărtat Potrivit dendrogramei, soluția optimă ar fi și alocarea a 3 clustere: primul cluster va include regiuni numerotate 1-50 (50 de regiuni), al doilea - numerotat 51-55 (5 regiuni), al treilea - ultimul număr de regiune 56. Metoda centrului de greutate Cu metoda „centrului de greutate”, distanța dintre clustere este luată ca distanță euclidiană dintre „centrele de greutate” ale clusterelor - media aritmetică a indicatorilor lor x i . Figura 7. Dendrograma. Metoda centrului de greutate Figura 7 arată că numărul optim de clustere este următorul: 1 cluster - 1-47 obiecte; 2 cluster - 48-54 obiecte (total 6); 3 clustere - 55 de obiecte; 4 clustere - 56 de obiecte. Principiul „conexiunii medii” În acest caz, distanța dintre clustere este egală cu valoarea medie a distanțelor dintre toate perechile posibile de observații, cu o observație luată dintr-un cluster, iar a doua, respectiv, dintr-un altul. Analiza tabelului etapelor de aglomerare a arătat că numărul optim de clustere este (56-52)=4. Să comparăm această concluzie cu concluzia obținută din analiza dendrogramei. Figura 8 arată că clusterul 1 va include obiecte numerotate 1-50, clusterul 2 - obiecte 51-54 (4 obiecte), clusterul 3 - regiunea 55, clusterul 4 - regiunea 56. Figura 8. Dendrograma. Metoda „conexiunii medii”
APLICAREA METODEI COMPONENTEI PRINCIPALE PENTRU PRELUCRAREA DATELOR STATISTICE MULTIDIMENSIONALE Sunt luate în considerare aspectele prelucrării datelor statistice multidimensionale ale evaluării de rating a elevilor pe baza aplicării metodei componentelor principale. Cuvinte cheie: analiza datelor multivariate, reducerea dimensionalității, analiza componentelor principale, rating. În practică, se întâlnește adesea o situație în care obiectul de studiu este caracterizat de o varietate de parametri, fiecare dintre ei măsurați sau evaluați. Analiza matricei de date inițiale obținute ca urmare a studiului mai multor obiecte de același tip este o sarcină practic de nerezolvat. Prin urmare, cercetătorul trebuie să analizeze conexiunile și interdependențele dintre parametrii inițiali pentru a elimina unii dintre ei sau a le înlocui cu un număr mai mic de orice funcții din aceștia, păstrând în același timp, dacă este posibil, toate informațiile conținute în aceștia. În acest sens, apar sarcinile de reducere a dimensionalității, adică trecerea de la matricea de date inițială la un număr semnificativ mai mic de indicatori selectați dintre cei inițiali sau obținuți printr-o anumită transformare (cu cea mai mică pierdere de informații conținute în matricea originală). ), și clasificare - separarea colecțiilor considerate de obiecte în grupuri omogene (într-un anumit sens). Dacă, pentru un număr mare de indicatori eterogene și interrelaționați stocastic, s-au obținut rezultatele unei anchete statistice a unui întreg set de obiecte, atunci pentru a rezolva problemele de clasificare și de reducere a dimensiunilor, ar trebui să se folosească instrumentele analizei statistice multivariate, în în special, metoda componentelor principale. Articolul propune o tehnică de aplicare a metodei componentelor principale pentru prelucrarea datelor statistice multivariate. Ca exemplu, este dată soluția problemei prelucrării statistice a rezultatelor multivariate ale evaluărilor studenților. 1.
Definirea si calculul componentelor principale..png" height="22 src="> caracteristici. Ca rezultat, obținem observații multidimensionale, fiecare dintre acestea putând fi reprezentată ca o observație vectorială unde https://pandia.ru/text/79/206/images/image005.png" height="22 src=">.png" height="22 src="> este simbolul operației de transpunere. Observațiile multidimensionale rezultate trebuie procesate statistic..png" height="22 src=">.png" height="22 src=">.png" width="132" height="25 src=">.png" width ="33" height="22 src="> permise transformări ale caracteristicilor studiate 0 " style="border-collapse:collapse"> este condiția de normalizare; – condiția de ortogonalitate Obținut printr-o transformare similară https://pandia.ru/text/79/206/images/image018.png" width="79" height="23 src="> și reprezintă principalele componente. Din ele, variabile cu minim varianțele sunt excluse din analiza ulterioară, adică..png" width="131" height="22 src="> în transformarea (2)..png" width="13" height="22 src="> a acestei matrice sunt egale cu varianţele componentelor principale . Astfel, prima componentă principală https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src="> este o astfel de combinație liniară normalizată-centrată a acestor indicatori , care dintre toate celelalte combinații similare, are cea mai mare dispersie..png" width="12" height="22 src="> –
vector matrice personalizat https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">.png" width="80" height="23 src= „> este o astfel de combinație liniară normalizată centrată a acestor indicatori, care nu este corelată cu https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src= ">. png" width="80" height="23 src="> sunt măsurate în unități diferite, apoi rezultatele studiului folosind componentele principale vor depinde în mod semnificativ de alegerea scalei și de natura unităților de măsură , iar combinațiile liniare rezultate ale variabilelor originale vor fi dificil de interpretat. În acest sens, cu diferite unități de măsură ale caracteristicilor inițiale DIV_ADBLOCK310 ">
Componentă Valori proprii inițiale Suma pătratului sarcinilor de rotație
Total % dispersie % cumulat Total % dispersie % cumulat
dimensiune0
5,442
90,700
90,700
3,315
55,246
55,246
,457
7,616
98,316
2,304
38,396
93,641
,082
1,372
99,688
,360
6,005
99,646
,009
,153
99,841
,011
,176
99,823
,007
,115
99,956
,006
,107
99,930
,003
,044
100,000
,004
,070
100,000
Metoda de extracție: Analiza componentelor principale.
Componentele matricei a
Componentă
X1 ,956
-,273
,084
,037
-,049
,015
X2 ,986
-,138
,035
-,080
,006
,013
X3 ,963
-,260
,034
,031
,060
-,010
X4 ,977
,203
,052
-,009
-,023
-,040
X5 ,966
,016
-,258
,008
-,008
,002
X6 ,861
,504
,060
,018
,016
,023
Metoda de extracție: Analiza componentelor principale.
A. Componente extrase: 6
Matricea componentelor rotite a
Componentă
X1 ,911
,384
,137
-,021
,055
,015
X2 ,841
,498
,190
,097
,000
,007
X3 ,900
,390
,183
-,016
-,058
-,002
X4 ,622
,761
,174
,022
,009
,060
X5 ,678
,564
,472
,007
,001
,005
X6 ,348
,927
,139
,001
-,004
-,016
Metoda de extracție: Analiza componentelor principale. Metoda de rotație: Varimax cu normalizare Kaiser.
A. Rotația converge în 4 iterații.

Model Coeficienți nestandardizați Coeficienți standardizați t Valoare
B Std. Eroare Beta
(Constant) 47414,184
1354,505
35,005
,001
Z1 26940,937
1366,763
,916
19,711
,001
Z2 6267,159
1366,763
,213
4,585
,001
Model R R-pătrat R-pătrat ajustat Std. eroare de estimare
dimensiune0
.941a ,885
,881
10136,18468
A. Predictori: (const) Z1, Z2
b. Variabila dependenta: Y
Etapă Clusterul a fuzionat cu Cote Etapa următoare
Clusterul 1 Clusterul 2 Clusterul 1 Clusterul 2
,003
,004
,004
,005
,005
,005
,005
,006
,007
,007
,009
,010
,010
,010
,010
,011
,012
,012
,012
,012
,012
,013
,014
,014
,014
,014
,015
,015
,016
,017
,018
,018
,019
,019
,020
,021
,021
,022
,024
,025
,027
,030
,033
,034
,042
,052
,074
,101
,103
,126
,163
,198
,208
,583
1,072

Etapă Clusterul a fuzionat cu Cote Etapa primei apariții a clusterului Etapa următoare
Clusterul 1 Clusterul 2 Clusterul 1 Clusterul 2
,003
,004
,004
,005
,005
,005
,005
,007
,009
,010
,010
,011
,011
,012
,012
,014
,014
,014
,017
,017
,018
,018
,019
,021
,022
,026
,026
,027
,034
,035
,035
,037
,037
,042
,044
,046
,063
,077
,082
,101
,105
,117
,126
,134
,142
,187
,265
,269
,275
,439
,504
,794
,902
1,673
2,449




![]()
https://pandia.ru/text/79/206/images/image030.png" width="17" height="22 src=">.png" width="56" height="23 src=">. După o astfel de transformare, componentele principale sunt analizate în raport cu valorile https://pandia.ru/text/79/206/images/image033.png" width="17" height="22 src="> , care este, de asemenea, o matrice de corelare https://pandia.ru/text/79/206/images/image035.png" width="162" height="22 src=">.png" width="13" height=" 22 src="> la i- a doua caracteristică sursă ..png" width="14" height="22 src=">.png" width="10" height="22 src="> este egală cu variația v- componenta principalăhttps://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> sunt utilizate în interpretarea semnificativă a componentelor principale..png" width ="20" height="22 src=">.png" width="251" height="25 src=">
Pentru a efectua calcule, observațiile vectoriale sunt agregate într-o matrice de probă, în care rândurile corespund caracteristicilor controlate, iar coloanele corespund obiectelor de studiu (dimensiunea matricei este https://pandia.ru/ text/79/206/images/image043.png" width="348 "height="67 src=">
După centrarea datelor inițiale, găsim matricea de corelație a eșantionului folosind formula
https://pandia.ru/text/79/206/images/image045.png" width="204" height="69 src=">
Elemente de matrice diagonală https://pandia.ru/text/79/206/images/image047.png" width="206" height="68 src=">
Elementele off-diagonale ale acestei matrice sunt estimări ale coeficienților de corelație dintre perechea corespunzătoare de caracteristici.
Compuneți ecuația caracteristică pentru matricea 0 " style="margin-left:5.4pt;border-collapse:collapse">

Găsește-i toate rădăcinile:
Acum, pentru a găsi componentele vectorilor principali, înlocuim succesiv valori numerice https://pandia.ru/text/79/206/images/image065.png" width="16" height="22 src=" >.png" width="102 "height="24 src=">
De exemplu, cu https://pandia.ru/text/79/206/images/image069.png" width="262" height="70 src=">
Este evident că sistemul de ecuații rezultat este consistent datorită omogenității și este nedefinit, adică are un număr infinit de soluții. Pentru a găsi singura soluție care ne interesează, folosim următoarele prevederi:
1. Pentru rădăcinile sistemului, relația poate fi scrisă
https://pandia.ru/text/79/206/images/image071.png" width="20" height="23 src="> – adunare algebrică j-al-lea element al oricărui i al-lea rând al matricei sistemului.
2. Prezența condiției de normalizare (2) asigură unicitatea soluției sistemului de ecuații considerat..png" width="13" height="22 src=">, sunt determinate în mod unic, cu excepția faptului că toate acestea poate schimba semnul simultan.Totuși, semnele componentelor vectori proprii nu joacă un rol semnificativ, deoarece modificarea lor nu afectează rezultatul analizei, ele pot servi doar pentru a indica tendințe opuse asupra componentei principale corespunzătoare.
Astfel, obținem propriul nostru vector https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">:
https://pandia.ru/text/79/206/images/image024.png" width="12" height="22 src="> verificați prin egalitate
https://pandia.ru/text/79/206/images/image076.png" width="503" height="22">
… … … … … … … … …
https://pandia.ru/text/79/206/images/image078.png" width="595" height="22 src=">
https://pandia.ru/text/79/206/images/image080.png" width="589" height="22 src=">
unde https://pandia.ru/text/79/206/images/image082.png" width="16" height="22 src=">.png" width="23" height="22 src="> sunt valorile standardizate ale caracteristicilor inițiale corespunzătoare.
Compuneți o matrice de transformare liniară ortogonală https://pandia.ru/text/79/206/images/image086.png" width="94" height="22 src=">
Deoarece, în conformitate cu proprietățile componentelor principale, suma variațiilor caracteristicilor inițiale este egală cu suma varianțelor tuturor componentelor principale, atunci, ținând cont de faptul că am considerat caracteristici inițiale normalizate, poate estima ce parte din variabilitatea totală a caracteristicilor inițiale explică fiecare dintre componentele principale. De exemplu, pentru primele două componente principale avem:
|
|
Astfel, în conformitate cu criteriul informativității utilizat pentru componentele principale găsite din matricea de corelație, primele șapte componente principale explică 88,97% din variabilitatea totală a celor cincisprezece caracteristici inițiale.
Folosind matricea de transformare liniară https://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> (pentru primele șapte componente principale):
https://pandia.ru/text/79/206/images/image090.png" width="16" height="22 src="> - numărul de diplome primite la concursul de teze științifice; https:/ /pandia .ru/text/79/206/images/image092.png" width="16" height="22 src=">.png" width="22" height="22 src=">.png" lățime =" 22" height="22 src=">.png" width="22" height="22 src="> – premii și premii luate la competițiile sportive regionale, regionale și urbane.
3..png" width="16" height="22 src=">(numărul de certificate bazat pe rezultatele participării la concursuri de lucrări științifice și de diplomă).
4..png" width="22" height="22 src=">(premii și premii luate la concursurile universitare).
6. A șasea componentă principală este corelată pozitiv cu DIV_ADBLOCK311">
4. A treia componentă principală este activitatea elevilor în procesul de învățământ.
5. A patra și a șasea componentă sunt diligența studenților în semestrele de primăvară, respectiv de toamnă.
6. A cincea componentă principală este gradul de participare la competițiile sportive universitare.
Pe viitor, pentru a efectua toate calculele necesare la identificarea componentelor principale, se propune utilizarea unor sisteme software de statistică specializate, precum STATISTICA, care vor facilita foarte mult procesul de analiză.
Procesul de identificare a principalelor componente descris în acest articol pe exemplul evaluării de rating a studenților este propus pentru a fi utilizat pentru atestarea de licență și masterat.
BIBLIOGRAFIE
1. Statistici aplicate: Clasificare și reducerea dimensiunii: Ref. ed. / , ; ed. . - M.: Finanțe și statistică, 1989. - 607 p.
2. Manual de statistică aplicată: în 2 volume: [per. din engleză] / ed. E. Lloyd, W. Lederman, . - M.: Finanţe şi statistică, 1990. - T. 2. - 526 p.
3. Statistici aplicate. Fundamentele econometriei. În 2 vol. T.1. Teoria probabilității și statistici aplicate: studii. pentru universități / , V. S. Mkhitaryan. - ed. a II-a, Ap. - M: UNITATEA-DANA, 2001. - 656 p.
4. Afifi, A. Analiza statistică: o abordare asistată de computer: [trad. din engleză] / A. Afifi, S. Eisen.- M .: Mir, 1982. - 488 p.
5. Dronov, Analiză statistică: manual. indemnizație / . - Barna 3. – 213 p.
6. Anderson, T. Introduction to multivariate statistical analysis / T. Anderson; pe. din engleza. [si etc.]; ed. . - M .: Stat. Editura Fiz.-Math. lit., 1963. - 500 p.
7. Lawley, D. Analiza factorială ca metodă statistică / D. Lawley, A. Maxwell; pe. din engleza. . – M.: Mir, 1967. – 144 p.
8. Dubrov, metode statistice: manual /,. - M.: Finanțe și statistică, 2003. - 352 p.
9. Kendall, M. Multivariate statistical analysis and time series / M. Kendall, A. Stuart;per. din engleza. , ; ed. , . – M.: Nauka, 1976. – 736 p.
10. Beloglazov, Analiza în probleme de calimetrie a educaţiei, Izv. A FUGIT. Teorie și sisteme de control. - 2006. - Nr. 6. - S. 39 - 52.
Materialul a fost primit de redacția pe 8 noiembrie 2011.
Lucrarea a fost realizată în cadrul programului țintă federal „Personalul științific și științific-pedagogic al Rusiei inovatoare” pentru 2009-2013. (contract de stat nr. P770).
Metoda componentei principale
Metoda componentei principale(Engleză) Analiza componentelor principale, PCA ) este una dintre principalele modalități de reducere a dimensionalității datelor, pierzând cea mai mică cantitate de informații. Inventat de K. Pearson (ing. Karl Pearson ) în d. Este utilizat în multe domenii, cum ar fi recunoașterea modelelor, viziunea computerizată, compresia datelor etc. Calculul componentelor principale se reduce la calculul vectorilor proprii și al valorilor proprii ale matricei de covarianță a datelor originale. Uneori se numește metoda componentei principale Transformarea Karhunen-Loeve(Engleză) Karhunen-Loeve) sau transformarea Hotelling (ing. Hotelling transform). Alte modalități de reducere a dimensiunii datelor sunt metoda componentelor independente, scalarea multidimensională, precum și numeroase generalizări neliniare: metoda curbelor și varietăților principale, metoda hărților elastice, căutarea celei mai bune proiecții (ing. Urmărirea proiecției), metodele rețelei neuronale ale „gâtului de sticlă”, etc.
Expunerea formală a problemei
Problema Analizei componentelor principale are cel puțin patru versiuni de bază:
- date aproximative prin varietăți liniare de dimensiune inferioară;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care răspândirea datelor (adică abaterea standard de la valoarea medie) este maximă;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care distanța pătratică medie dintre puncte este maximă;
- pentru o variabilă aleatoare multidimensională dată, construiți o astfel de transformare ortogonală a coordonatelor încât, ca urmare, corelațiile dintre coordonatele individuale să dispară.
Primele trei versiuni operează pe seturi finite de date. Sunt echivalente și nu folosesc nicio ipoteză despre generarea datelor statistice. A patra versiune operează cu variabile aleatorii. Mulțimi finite apar aici ca mostre dintr-o distribuție dată și soluție de trei a primelor probleme – ca o aproximare la „adevărata” transformare Karhunen-Loeve. Acest lucru ridică o întrebare suplimentară și nu chiar trivială cu privire la acuratețea acestei aproximări.
Aproximarea datelor prin varietăți liniare
Ilustrație pentru celebra lucrare a lui K. Pearson (1901): sunt date puncte de pe un plan, - distanța de la o linie dreaptă. Se caută o linie dreaptă care să minimizeze suma
Metoda componentelor principale a început cu problema celei mai bune aproximări a unui set finit de puncte prin linii drepte și plane (K. Pearson, 1901). Având în vedere un set finit de vectori. Pentru fiecare dintre toate varietățile liniare dimensionale, găsiți astfel încât suma abaterilor pătrate de la este minimă:
,unde este distanța euclidiană de la un punct la o varietate liniară. Orice varietate liniară -dimensională din poate fi definită ca un set de combinații liniare, în care parametrii trec pe linia reală și este un set ortonormal de vectori
,unde este norma euclidiană, este produsul scalar euclidian sau sub formă de coordonate:
.Rezolvarea problemei de aproximare pentru este dată de o mulțime de varietăți liniare imbricate , . Aceste varietăți liniare sunt definite de un set ortonormal de vectori (vectori de componente principale) și un vector . Vectorul este căutat ca soluție la problema de minimizare pentru:
.Vectorii componente principale pot fi găsiți ca soluții la probleme de optimizare de același tip:
1) centralizați datele (scădeți media): . Acum; 2) găsiți prima componentă principală ca soluție a problemei; . Dacă soluția nu este unică, atunci alegeți una dintre ele. 3) Scădeți din date proiecția pe prima componentă principală: ; 4) găsiți a doua componentă principală ca soluție a problemei. Dacă soluția nu este unică, atunci alegeți una dintre ele. … 2k-1) Scădeți proiecția pe -a componentă principală (amintim că proiecțiile asupra componentelor principale anterioare au fost deja scăzute): ; 2k) găsiți a k-a componentă principală ca soluție a problemei: . Dacă soluția nu este unică, atunci alegeți una dintre ele. …
La fiecare pas pregătitor, scădem proiecția pe componenta principală anterioară. Vectorii găsiți sunt ortonormali pur și simplu ca urmare a rezolvării problemei de optimizare descrise, totuși, pentru a preveni încălcarea ortogonalității reciproce a vectorilor componentelor principale ale erorilor de calcul, ei pot fi incluși în condițiile problemei de optimizare.
Neunicitatea în definiție, pe lângă banala arbitrar în alegerea semnului (și rezolva aceeași problemă), poate fi mai semnificativă și provine, de exemplu, din condițiile de simetrie a datelor. Ultima componentă principală este un vector unitar ortogonal cu toate precedentele.
Căutați proiecții ortogonale cu cea mai mare împrăștiere

Prima componentă principală maximizează varianța eșantionului a proiecției datelor
Să ni se dea un set centrat de vectori de date (media aritmetică este zero). Sarcina este de a găsi o astfel de transformare ortogonală într-un nou sistem de coordonate, pentru care următoarele condiții ar fi adevărate:
Teoria descompunerii valorii singulare a fost creată de J. J. Sylvester (ing. James Joseph Sylvester ) în d. și este expus în toate ghiduri detaliate pe teoria matricei.
Un algoritm iterativ simplu de descompunere a valorii singulare
Procedura principală este căutarea celei mai bune aproximări a unei matrice arbitrare printr-o matrice de forma (unde este un vector dimensional și este un vector dimensional) prin metoda celor mai mici pătrate:
Soluția acestei probleme este dată de iterații succesive folosind formule explicite. Pentru un vector fix, valorile care oferă minimul formei sunt determinate în mod unic și explicit din egalități:
În mod similar, pentru un vector fix, se determină următoarele valori:
Ca o aproximare inițială a vectorului, luăm un vector aleatoriu de unitate de lungime, calculăm vectorul , apoi calculăm vectorul pentru acest vector etc. Fiecare pas reduce valoarea lui . Micimea scăderii relative a valorii pasului de iterație funcțional minimizat () sau micimea valorii în sine este utilizată ca criteriu de oprire.
Ca urmare, pentru matrice, am obținut cea mai bună aproximare printr-o matrice de formă (aici, suprascriptul indică numărul de aproximare). În continuare, scădem matricea rezultată din matrice, iar pentru matricea de deviație obținută căutăm din nou cea mai bună aproximare de același tip și așa mai departe, până când, de exemplu, norma devine suficient de mică. Ca rezultat, am obținut o procedură iterativă de descompunere a unei matrice ca sumă de matrice de rang 1, adică . Presupunem și normalizăm vectorii: Ca rezultat, se obține o aproximare a numerelor singulare și a vectorilor singulari (dreapta - și stânga - ).
Avantajele acestui algoritm includ simplitatea sa excepțională și capacitatea de a-l transfera aproape fără modificări ale datelor cu lacune, precum și date ponderate.
Există diverse modificări ale algoritmului de bază care îmbunătățesc precizia și stabilitatea. De exemplu, vectorii componentelor principale pentru diferite ar trebui să fie ortogonali „prin construcție”, cu toate acestea, cu un număr mare de iterații (dimensiune mare, multe componente), se acumulează mici abateri de la ortogonalitate și poate fi necesară o corecție specială la fiecare pas, asigurându-i ortogonalitatea față de componentele principale găsite anterior.
Metoda de descompunere a valorii singulare a tensorilor și a componentei principale a tensorilor
Adesea, un vector de date are structura suplimentară a unui tabel dreptunghiular (de exemplu, o imagine plată) sau chiar a unui tabel multidimensional - adică un tensor : , . În acest caz, este de asemenea eficient să folosiți descompunerea valorii singulare. Definiția, formulele de bază și algoritmii sunt transferate practic fără modificări: în loc de o matrice de date, avem o valoare -index , unde primul indice este numărul punctului de date (tensor).
Procedura principală este căutarea celei mai bune aproximări a tensorului printr-un tensor de formă (unde - - vector dimensional ( - număr de puncte de date), - vector dimensiune la ) prin metoda celor mai mici pătrate:
Soluția acestei probleme este dată de iterații succesive folosind formule explicite. Dacă toți vectorii factori sunt dați cu excepția unuia, atunci acesta rămas este determinat în mod explicit din condiții minime suficiente.
Ca o aproximare inițială a vectorilor (), luăm vectori aleatori de lungime unitară, calculăm vectorul , apoi pentru acest vector și acești vectori calculăm vectorul etc. (ciclați prin indici) Fiecare pas reduce valoarea lui . Algoritmul converge evident. Ca criteriu de oprire se utilizează micșorarea scăderii relative a valorii funcționalului care trebuie minimizat pe ciclu sau micimea valorii în sine. Mai departe, scădem aproximarea rezultată din tensor și pentru rest căutăm din nou cea mai bună aproximare de același tip și așa mai departe, până când, de exemplu, norma următorului rest devine suficient de mică.
Această descompunere a valorii singulare multicomponente (metoda tensorală a componentelor principale) este utilizată cu succes în procesarea imaginilor, a semnalelor video și, mai larg, a oricăror date care au o structură tabelară sau tensorală.
Matricea de transformare în componentele principale
Matricea de transformare a datelor în componente principale constă din vectori de componente principale aranjați în ordinea descrescătoare a valorilor proprii:
(înseamnă transpunere),Adică, matricea este ortogonală.
Cea mai mare parte a variației datelor va fi concentrată în primele coordonate, ceea ce vă permite să vă deplasați într-un spațiu dimensional inferior.
Dispersia reziduala
Lasă datele să fie centrate, . Când vectorii de date sunt înlocuiți cu proiecția lor pe primele componente principale, se introduce pătratul mediu al erorii pentru un vector de date:
unde sunt valorile proprii ale matricei de covarianță empirice, dispuse în ordine descrescătoare, ținând cont de multiplicitate.
Această valoare este numită dispersie reziduala. Valoare
numit varianță explicată. Suma lor este egală cu varianța eșantionului. Eroarea relativă pătrată corespunzătoare este raportul dintre variația reziduală și varianța eșantionului (adică proporție de varianță inexplicabilă):
Eroarea relativă evaluează aplicabilitatea metodei componentelor principale cu proiecție pe primele componente.
cometariu: în majoritatea algoritmilor de calcul, valorile proprii cu vectorii proprii corespunzători - componentele principale sunt calculate în ordinea „de la cel mai mare la cel mai mic”. Pentru a calcula, este suficient să calculați primele valori proprii și urma matricei de covarianță empirică (suma elementelor diagonale, adică variațiile de-a lungul axelor). Apoi
Selectarea componentelor principale de către regula Kaiser
Abordarea țintă pentru estimarea numărului de componente principale după proporția necesară a varianței explicate este întotdeauna aplicabilă formal, dar implicit presupune că nu există nicio separare în „semnal” și „zgomot”, și orice precizie predeterminată are sens. Prin urmare, o altă euristică este adesea mai productivă, bazată pe ipoteza prezenței unui „semnal” (dimensiune relativ mică, amplitudine relativ mare) și „zgomot” (dimensiune mare, amplitudine relativ mică). Din acest punct de vedere, metoda componentelor principale funcționează ca un filtru: semnalul este conținut în principal în proiecția pe primele componente principale, iar la celelalte componente proporția de zgomot este mult mai mare.
Întrebare: cum se estimează numărul de componente principale necesare dacă raportul semnal-zgomot nu este cunoscut în prealabil?
Cea mai simplă și mai veche metodă de selecție a componentelor principale oferă regula lui Kaiser(Engleză) regula lui Kaiser): acele componente principale sunt semnificative pentru care
adică depășește media (varianța medie a eșantionului a coordonatelor vectorului de date). Regula lui Kaiser funcționează bine în cazurile simple în care există mai multe componente principale cu , care sunt mult mai mari decât media, iar restul valorilor proprii sunt mai mici decât aceasta. În cazuri mai complexe, poate da prea multe componente principale semnificative. Dacă datele sunt normalizate la variația eșantionului unitar de-a lungul axelor, atunci regula Kaiser ia o formă deosebit de simplă: numai acele componente principale sunt semnificative pentru care
Estimarea numărului de componente principale utilizând regula bastonului rupt

Exemplu: estimarea numărului de componente principale prin regula bastonului rupt în dimensiunea 5.
Una dintre cele mai populare abordări euristice pentru estimarea numărului de componente principale necesare este regula bastonului rupt(Engleză) Model stick rupt). Setul de valori proprii normalizate la suma unitară (, ) este comparat cu distribuția lungimilor fragmentelor unui baston de lungime unitară rupte la al treilea punct ales aleatoriu (punctele de rupere sunt alese independent și sunt distribuite egal pe lungimea a bastonului). Fie () lungimile pieselor de trestie obtinute, numerotate in ordinea descrescatoare a lungimii: . Nu este greu de găsit așteptările matematice:
După regula bastonului rupt, vectorul propriu (în ordinea descrescătoare a valorilor proprii) este stocat în lista componentelor principale dacă
Pe Fig. este dat un exemplu pentru cazul 5-dimensional:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.De exemplu, selectat
=0.5; =0.3; =0.1; =0.06; =0.04.Conform regulii unui baston rupt, în acest exemplu ar trebui lăsate 2 componente principale:
Potrivit utilizatorilor, regula bastonului rupt tinde să subestimeze numărul de componente principale semnificative.
Normalizare
Normalizare după reducerea la componentele principale
După proiecția pe primele componente principale cu este convenabil să se normalizeze la varianța unitară (eșantionului) de-a lungul axelor. Dispersia de-a lungul celei de-a doua componente principale este egală cu ), deci pentru normalizare este necesar să se împartă coordonatele corespunzătoare la . Această transformare nu este ortogonală și nu păstrează produsul punctual. După normalizare, matricea de covarianță a proiecției datelor devine unitate, proiecțiile către oricare două direcții ortogonale devin valori independente și orice bază ortonormală devine baza componentelor principale (reamintim că normalizarea modifică raportul de ortogonalitate al vectorilor). Maparea de la spațiul de date inițial la primele componente principale împreună cu normalizarea este dată de matrice
.Această transformare este cea mai adesea numită transformarea Karhunen-Loeve. Aici, sunt vectori coloană, iar superscript înseamnă transpunere.
Normalizarea înainte de calcularea componentelor principale
Avertizare: nu trebuie confundată normalizarea efectuată după transformarea în componentele principale cu normalizarea și „adimensional” atunci când preprocesarea datelor efectuate înainte de calcularea componentelor principale. Pre-normalizarea este necesară pentru o alegere rezonabilă a unei metrici în care se va calcula cea mai bună aproximare a datelor sau se vor căuta direcțiile celei mai mari împrăștiere (care este echivalentă). De exemplu, dacă datele sunt vectori tridimensionali de „metri, litri și kilograme”, atunci folosind distanța euclidiană standard, o diferență de 1 metru în prima coordonată va avea aceeași contribuție ca o diferență de 1 litru în a doua. , sau 1 kg în al treilea . De obicei, sistemele de unități în care sunt prezentate datele sursă nu reflectă cu acuratețe ideile noastre despre scările naturale de-a lungul axelor și se realizează „fără dimensiune”: fiecare coordonată este împărțită într-o anumită scară determinată de date, de scopuri. a prelucrării acestora și a proceselor de măsurare și colectare a datelor.
Există trei abordări standard, esențial diferite, pentru o astfel de normalizare: varianța unitară de-a lungul axelor (scalele de-a lungul axelor sunt egale cu abaterile pătratice medii - după această transformare, matricea de covarianță coincide cu matricea coeficienților de corelație), pe precizie egală de măsurare(scara de-a lungul axei este proporțională cu precizia de măsurare a unei valori date) și pe revendicări egaleîn problemă (scara de-a lungul axei este determinată de precizia necesară a prognozei unei anumite valori sau de distorsiunea permisă a acesteia - nivelul de toleranță). Alegerea preprocesării este influențată de enunțul semnificativ al problemei, precum și de condițiile de colectare a datelor (de exemplu, dacă colectarea datelor este fundamental incompletă și datele vor fi încă primite, atunci nu este rațional să alegeți strict normalizarea după variația unității, chiar dacă aceasta corespunde sensului problemei, deoarece aceasta implică renormalizarea tuturor datelor după primirea unei noi porțiuni; este mai rezonabil să alegeți o scară care să estimeze aproximativ abaterea standard și apoi să nu o modificați) .
Pre-normalizarea la variația unității de-a lungul axelor este distrusă prin rotația sistemului de coordonate dacă axele nu sunt componente principale, iar normalizarea în timpul preprocesării datelor nu înlocuiește normalizarea după reducerea la componentele principale.
Analogie mecanică și analiza componentelor principale pentru datele ponderate
Dacă atribuim o unitate de masă fiecărui vector de date, atunci matricea de covarianță empirică va coincide cu tensorul de inerție al acestui sistem de mase punctuale (împărțit la masa totală), iar problema componentelor principale va coincide cu problema aducerii tensor de inerție față de axele principale. Puteți folosi libertate suplimentară în alegerea valorilor de masă pentru a ține cont de importanța punctelor de date sau de fiabilitatea valorilor acestora (masele mai mari sunt atribuite datelor importante sau date din surse mai fiabile). Dacă vectorului de date i se dă o masă, atunci în loc de matricea de covarianță empirică obținem
Toate operațiunile ulterioare de reducere la componentele principale sunt efectuate în același mod ca în versiunea principală a metodei: căutăm o bază proprie ortonormală, ordonând-o în ordinea descrescătoare a valorilor proprii, estimând eroarea medie ponderată a aproximării datelor prin prima componente (prin sumele valorilor proprii), normalizare etc.
Mai mult mod general cântărirea dă maximizarea sumei ponderate a distanțelor pe perechiîntre proiecţii. Pentru fiecare două puncte de date, se introduce o pondere; Și . În loc de matricea de covarianță empirică, folosim
Pentru , matricea simetrică este pozitivă definită deoarece forma pătratică este pozitivă:
În continuare, căutăm o bază proprie ortonormală, o aranjam în ordinea descrescătoare a valorilor proprii, estimăm eroarea medie ponderată a aproximării datelor de către primele componente etc. - exact la fel ca în algoritmul principal.
Se aplică această metodă dacă există cursuri: pentru clase diferite, ponderea este aleasă să fie mai mare decât pentru punctele din aceeași clasă. Ca urmare, în proiecția pe componentele principale ponderate, diferitele clase sunt „depărtate” cu o distanță mai mare.
Altă aplicație - reducerea influenței abaterilor mari(achizitori, ing. Outlier ), care poate distorsiona imaginea datorită utilizării distanței rms: dacă alegeți , atunci influența abaterilor mari va fi redusă. Astfel, modificarea descrisă a metodei componentelor principale este mai robustă decât cea clasică.
Terminologie specială
În statistică, atunci când se utilizează metoda componentelor principale, se folosesc mai mulți termeni speciali.
Data Matrix; fiecare rând este un vector preprocesate date ( centrat si drept normalizat), numărul de rânduri - (numărul de vectori de date), numărul de coloane - (dimensiunea spațiului de date);
Încărcare matrice(Încărcări) ; fiecare coloană este vectorul componentei principale, numărul de rânduri este (dimensiunea spațiului de date), numărul de coloane este (numărul de vectori componente principale selectate pentru proiecție);
Matricea de facturare(scoruri) ; fiecare rând este proiecția vectorului de date pe componentele principale; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea scorului Z(scoruri Z); fiecare rând este proiecția vectorului de date pe componentele principale, normalizată la varianța eșantionului unitar; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea erorilor(sau resturi) (Erori sau reziduuri) .
Formula de baza:
Limite de aplicabilitate și limitări ale eficacității metodei
Metoda componentei principale este întotdeauna aplicabilă. Afirmația larg răspândită că este aplicabilă numai datelor distribuite în mod normal (sau distribuțiilor apropiate de normal) este incorectă: în formularea originală a lui K. Pearson, problema aproximări un set finit de date și nici măcar nu există o ipoteză despre generarea lor statistică, ca să nu mai vorbim despre distribuție.
Cu toate acestea, metoda nu reduce întotdeauna eficient dimensionalitatea sub anumite restricții privind precizia. Liniile drepte și planele nu oferă întotdeauna o bună aproximare. De exemplu, datele pot urma o curbă cu o bună acuratețe, iar această curbă poate fi dificil de localizat în spațiul de date. În acest caz, metoda componentelor principale pentru o acuratețe acceptabilă va necesita mai multe componente (în loc de una) sau nu va oferi deloc reducerea dimensionalității cu o acuratețe acceptabilă. Pentru a trata astfel de componente principale „curbe”, sunt inventate metoda varietăților principale și diferite versiuni ale metodei componentelor principale neliniare. Mai multe probleme pot furniza date de topologie complexe. De asemenea, au fost inventate diverse metode pentru a le aproxima, cum ar fi hărți Kohonen auto-organizate, gaz neural sau gramaticile topologice. Dacă datele sunt generate statistic cu o distribuție foarte nenormală, atunci este util să trecem de la componentele principale la componente independente, care nu mai sunt ortogonale în produsul punctual original. În sfârșit, pentru o distribuție izotropă (chiar și una normală), în loc de un elipsoid de împrăștiere, obținem o sferă și este imposibil să reducem dimensiunea prin metode de aproximare.
Exemple de utilizare
Vizualizarea datelor
Vizualizarea datelor este o prezentare sub formă vizuală a datelor experimentale sau a rezultatelor unui studiu teoretic.
Prima alegere în vizualizarea unui set de date este proiecția ortogonală pe planul primelor două componente principale (sau spațiul 3D al primelor trei componente principale). Planul de proiectare este în esență un „ecran” plat bidimensional poziționat în așa fel încât să ofere o „imagine” a datelor cu cea mai mică distorsiune. O astfel de proiecție va fi optimă (dintre toate proiecțiile ortogonale pe diferite ecrane bidimensionale) din trei aspecte:
- Suma minimă a distanțelor pătrate de la punctele de date la proiecțiile pe planul primelor componente principale, adică ecranul este situat cât mai aproape de norul de puncte.
- Suma minimă a distorsiunilor pătratului distanțelor dintre toate perechile de puncte din norul de date după proiectarea punctelor în plan.
- Suma minimă a distorsiunilor pătrate ale distanței dintre toate punctele de date și „centrul lor de greutate”.
Vizualizarea datelor este una dintre cele mai utilizate aplicații ale analizei componentelor principale și ale generalizărilor sale neliniare.
Compresie imagini și video
Pentru a reduce redundanța spațială a pixelilor atunci când se codifică imagini și videoclipuri, sunt utilizate transformări liniare ale blocurilor de pixeli. Cuantificarea ulterioară a coeficienților obținuți și codarea fără pierderi fac posibilă obținerea unor coeficienți de compresie semnificativi. Utilizarea transformării PCA ca transformare liniară este optimă pentru unele tipuri de date în ceea ce privește dimensiunea datelor rezultate cu aceeași distorsiune. În prezent, această metodă nu este utilizată în mod activ, în principal din cauza complexității mari de calcul. De asemenea, compresia datelor poate fi realizată prin eliminarea ultimilor coeficienți de transformare.
Reducerea zgomotului în imagini
Chimiometrie
Metoda componentei principale este una dintre metodele principale din chimiometrie. Chimiometrie ). Vă permite să împărțiți matricea datelor inițiale X în două părți: „cu sens” și „zgomot”. Conform celei mai populare definiții, „Chimiometria este disciplina chimică care aplică metode matematice, statistice și alte metode bazate pe logica formală pentru a construi sau selecta metode de măsurare optime și proiecte experimentale și pentru a extrage cele mai importante informații în analiza datelor experimentale. "
Psihodiagnostic
- analiza datelor (descrierea rezultatelor sondajelor sau altor studii, prezentate sub formă de rețele de date numerice);
- descrierea fenomenelor sociale (construcția de modele de fenomene, inclusiv modele matematice).
În științe politice, metoda componentei principale a fost instrumentul principal al proiectului „Atlasul politic al modernității” pentru analiza liniară și neliniară a evaluărilor a 192 de țări ale lumii conform a cinci indici integrali special dezvoltați (nivelul de trai, standardul internațional). influență, amenințări, statalitate și democrație). Pentru cartografierea rezultatelor acestei analize a fost dezvoltat un GIS (Geoinformation System) special care combină spațiul geografic cu spațiul caracteristic. Hărțile de date ale atlasului politic au fost create, de asemenea, utilizând colectoare principale 2D în spațiul țării 5D ca fundal. Diferența dintre o hartă de date și o hartă geografică este că pe o hartă geografică sunt în apropiere obiecte care au coordonate geografice similare, în timp ce pe o hartă de date sunt în apropiere obiecte (țări) cu caracteristici (indici) similare.
Sursa analizei este matricea de date
dimensiuni  , a cărei i-a linie caracterizează i-a observație (obiect) pentru toți k indicatori
, a cărei i-a linie caracterizează i-a observație (obiect) pentru toți k indicatori  . Se normalizează datele inițiale, pentru care se calculează valorile medii ale indicatorilor
. Se normalizează datele inițiale, pentru care se calculează valorile medii ale indicatorilor  , precum și valorile abaterilor standard
, precum și valorile abaterilor standard  . Apoi matricea valorilor normalizate
. Apoi matricea valorilor normalizate

cu elemente 
Se calculează matricea coeficienților de corelație perechi:

Elementele unice sunt situate pe diagonala principală a matricei  .
.
Modelul de analiză a componentelor este construit prin prezentarea datelor normalizate originale ca o combinație liniară a componentelor principale:

Unde  - „greutate”, adică sarcina factorului
- „greutate”, adică sarcina factorului  -a componenta principala pe
-a componenta principala pe  -a variabila;
-a variabila;
 -sens
-sens  componenta principală pentru
componenta principală pentru  a-a observație (obiect), unde
a-a observație (obiect), unde  .
.
În formă de matrice, modelul are forma

Aici  - matricea componentelor principale ale dimensiunii
- matricea componentelor principale ale dimensiunii  ,
,
 - matricea încărcărilor factoriale de aceeași dimensiune.
- matricea încărcărilor factoriale de aceeași dimensiune.
Matrice  descrie
descrie  observatii in spatiu
observatii in spatiu  componentele principale. În acest caz, elementele matricei
componentele principale. În acest caz, elementele matricei  sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că
sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că 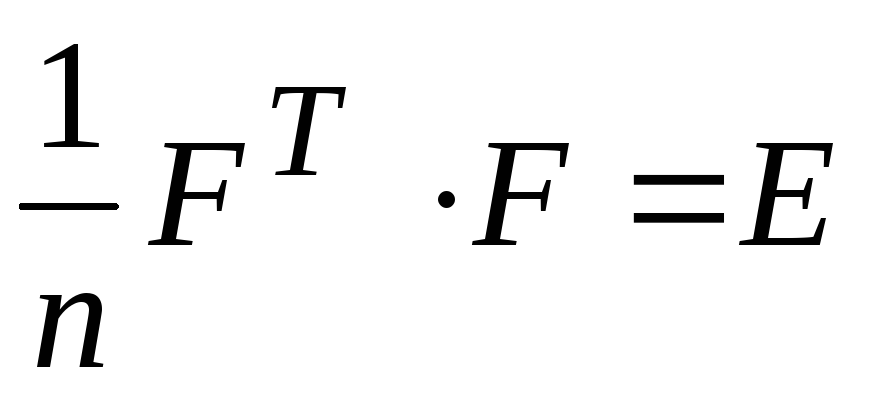 , Unde
, Unde  este matricea identitară a dimensiunii
este matricea identitară a dimensiunii  .
.
Element  matrici
matrici  caracterizează strânsoarea relaţiei liniare dintre variabila iniţială
caracterizează strânsoarea relaţiei liniare dintre variabila iniţială  si componenta principala
si componenta principala  , prin urmare, ia valorile
, prin urmare, ia valorile  .
.
Matricea de corelație  poate fi exprimat în termenii matricei de încărcare factorială
poate fi exprimat în termenii matricei de încărcare factorială  .
.
Unitățile sunt situate de-a lungul diagonalei principale a matricei de corelație și, prin analogie cu matricea de covarianță, ele reprezintă variațiile matricei utilizate  -caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem
-caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem  -caracteristici din setul de mostre de volum
-caracteristici din setul de mostre de volum  este egală cu suma acestor unități, adică egală cu urma matricei de corelaţie
este egală cu suma acestor unități, adică egală cu urma matricei de corelaţie  .
.
Matricele de corelație pot fi convertite într-o matrice diagonală, adică o matrice, toate valorile cărora, cu excepția celor diagonale, sunt egale cu zero:
 ,
,
Unde  este o matrice diagonală cu valori proprii pe diagonala sa principală
este o matrice diagonală cu valori proprii pe diagonala sa principală  matricea de corelatie,
matricea de corelatie,  este o matrice ale cărei coloane sunt vectorii proprii ai matricei de corelație
este o matrice ale cărei coloane sunt vectorii proprii ai matricei de corelație  . Deoarece matricea R este definită pozitiv, i.e. minorii săi principali sunt pozitivi, apoi toate valorile proprii
. Deoarece matricea R este definită pozitiv, i.e. minorii săi principali sunt pozitivi, apoi toate valorile proprii  pentru orice
pentru orice  .
.
Valori proprii  se găsesc ca rădăcini ale ecuaţiei caracteristice
se găsesc ca rădăcini ale ecuaţiei caracteristice

Vector propriu  corespunzătoare valorii proprii
corespunzătoare valorii proprii  matricea de corelare
matricea de corelare  , este definit ca o soluție diferită de zero a ecuației
, este definit ca o soluție diferită de zero a ecuației

Vector propriu normalizat  egală
egală

Dispariția termenilor în afara diagonalei înseamnă că caracteristicile devin independente unele de altele ( 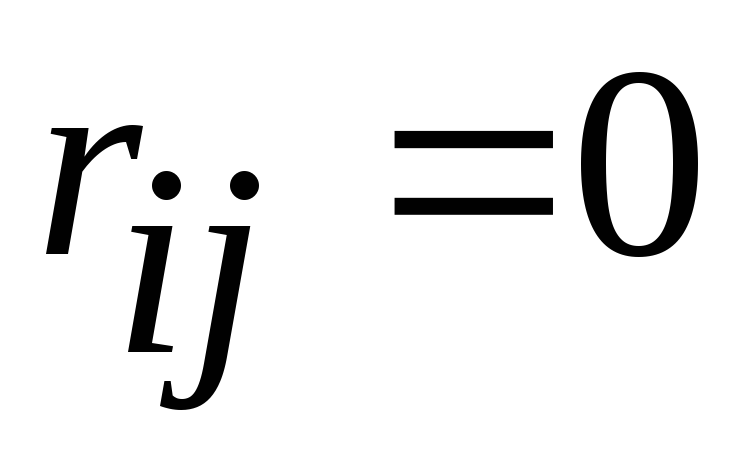 la
la  ).
).
Varianta totala a intregului sistem  variabilele din eșantion rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii
variabilele din eșantion rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii  matricea de corelație pentru fiecare dintre
matricea de corelație pentru fiecare dintre 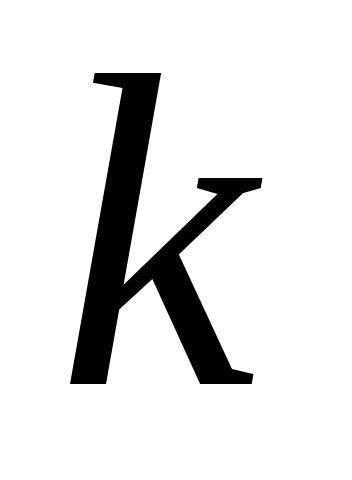 -semne. Suma acestor valori proprii
-semne. Suma acestor valori proprii  este egală cu urma matricei de corelație, i.e.
este egală cu urma matricei de corelație, i.e.  , adică numărul de variabile. Aceste valori proprii sunt valorile variației caracteristicii
, adică numărul de variabile. Aceste valori proprii sunt valorile variației caracteristicii  în condiţiile în care semnele ar fi independente unele de altele.
în condiţiile în care semnele ar fi independente unele de altele.
În metoda componentelor principale, matricea de corelație este mai întâi calculată din datele inițiale. Apoi, se realizează transformarea lui ortogonală și, prin aceasta, se găsesc încărcările factorilor  pentru toți
pentru toți  variabile şi
variabile şi  factori (matricea sarcinilor factorilor), valori proprii
factori (matricea sarcinilor factorilor), valori proprii  și determinați ponderile factorilor.
și determinați ponderile factorilor.
Matricea de încărcare a factorilor A poate fi definită ca 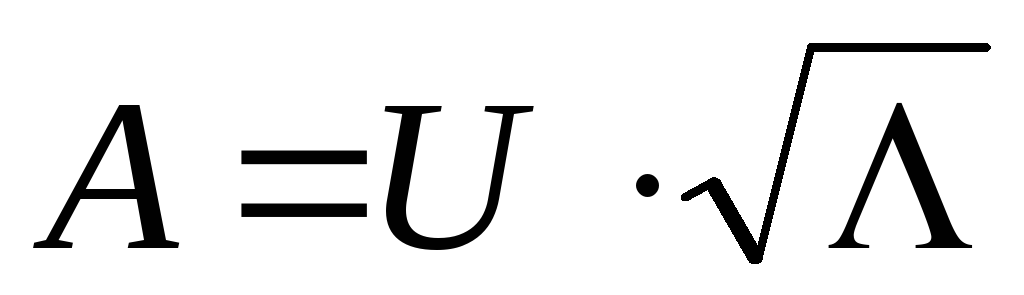 , A
, A  -a coloană a matricei A - ca
-a coloană a matricei A - ca  .
.
Ponderea factorilor  sau
sau  reflectă ponderea în variația totală contribuită de acest factor.
reflectă ponderea în variația totală contribuită de acest factor.
Sarcinile factorilor variază de la -1 la +1 și sunt analoge cu coeficienții de corelație. În matricea încărcărilor factorilor, este necesar să se facă distincția între sarcini semnificative și nesemnificative folosind testul t al lui Student.  .
.
Suma încărcărilor pătrate  - al-lea factor în total
- al-lea factor în total  -caracteristicile este egală cu valoarea proprie a acestui factor
-caracteristicile este egală cu valoarea proprie a acestui factor  . Apoi
. Apoi  -contribuția variabilei i-a în % la formarea factorului j-lea.
-contribuția variabilei i-a în % la formarea factorului j-lea.
Suma pătratelor tuturor încărcărilor de factori dintr-un rând este egală cu unu, varianța completă a unei variabile și a tuturor factorilor din toate variabilele este egală cu varianța totală (adică urmea sau ordinea matricei de corelație sau suma a valorilor sale proprii)  .
.
În general, structura factorială a caracteristicii i-a este reprezentată în formă  , care include doar sarcini semnificative. Folosind matricea de încărcare a factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a eșantionului original folosind formula:
, care include doar sarcini semnificative. Folosind matricea de încărcare a factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a eșantionului original folosind formula:
 ,
,
Unde  este valoarea factorului j-a din a-a observație,
este valoarea factorului j-a din a-a observație,  - valoarea standardizată a trăsăturii i-a a observației a-lea a eșantionului original;
- valoarea standardizată a trăsăturii i-a a observației a-lea a eșantionului original;  - sarcina factorului,
- sarcina factorului,  este valoarea proprie corespunzătoare factorului j. Aceste valori calculate
este valoarea proprie corespunzătoare factorului j. Aceste valori calculate  sunt utilizate pe scară largă pentru reprezentarea grafică a rezultatelor analizei factoriale.
sunt utilizate pe scară largă pentru reprezentarea grafică a rezultatelor analizei factoriale.
În conformitate cu matricea încărcărilor factorilor, matricea de corelație poate fi restabilită:  .
.
Porțiunea de varianță a unei variabile explicată de componentele principale se numește comunalitate.
 ,
,
Unde  este numărul variabilei și
este numărul variabilei și  - numărul componentei principale. Coeficienții de corelație reconstruiți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile comunității.
- numărul componentei principale. Coeficienții de corelație reconstruiți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile comunității.
Contribuție specifică  componenta principală este determinată de formulă
componenta principală este determinată de formulă
 .
.
Contribuția totală a  componentele principale se determină din expresie
componentele principale se determină din expresie
 .
.
Folosit de obicei pentru analiză  primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
Matricea de încărcare a factorilor A este utilizată pentru a interpreta componentele principale, iar valorile de peste 0,5 sunt de obicei luate în considerare.
Valorile componentelor principale sunt date de matrice